はじめに
この記事はEnigmo Advent Calendar 2018の25日目です。
BUYMAでプロダクトマネージャー・ディレクターのようなことをしています。 機械学習に関する案件を初めて進めてみようと思い、 プロダクトマネージャー・ディレクター目線で 、やってきたことや学んだことをまとめます。
知識がなくてもプロジェクトや案件は進めれるとは思いますが、ある程度理解があることで、プロジェクトの幅も広がりますし、エンジニアとのコミュニケーションも円滑になりますし、 何より自分も楽しいです 。
また、もし機械学習に関して知見がない会社でプロジェクトを進めていく場合の参考になればと思います。
この記事の対象者
非エンジニア の プロダクトマネージャー・ディレクター 向けの記事です。
対象ではない方
全体の流れ
1.基本知識のインプット 2.実際にコーディングもやってみる 3.プロジェクト・案件にするまで
基本知識のインプット
ゼロからスタートする場合は、何から初めてよいのか?と悩むことも多いと思います。
一番最初にやってみた
まず参考にしたのが下記の記事 【保存版・初心者向け】独学でAIエンジニアになりたい人向けのオススメの勉強方法
網羅されていて、わかりやすいが、プロダクトマネージャー・ディレクターとしては、ここまではいらない。(実際にやってみて途中でいろいろ挫折。時間もかかる)
その中で、やってきたことをプロダクトマネージャー・ディレクター向けに書きます。 下記に出てくる記事や本を読めば、最低限は大丈夫ではないかなと思います。
STEP1:まず機械学習を知る
例に漏れずここから。流し読みでもかなり面白い。
 人工知能は人間を超えるか (角川EPUB選書)
人工知能は人間を超えるか (角川EPUB選書)
読み終わると
- AIってなんかすごそうってなる
- なんかすごくAIがわかった気持ちになれる
- エンジニアが言っていることが何となくわかるようになる
STEP2 : Pythonを知る
実際にコーディングもやることを考えると、ディレクターでもPythonは必須です。 全く触れたことがなかったので、本当に簡単なところから。
ドットインストール
動画を通勤中や移動中に見る。理解しようとせず最初は、流し見でよいと思う。 3回ほど聞くと、なんとなくわかってくる。
終わると
Python3入門ノート
非常にわかりやすかった。 エンジニアではないので、日々コーディングしないと言語は習得が難しいので、なんとなく理解する程度で、読み飛ばす。 その中でも、読んでおくとよさそうのは、 Part3の「Numpyの配列」 ただ、読んでもほぼ忘れる。
あと、読み進める中で気になるところは、写経して実際にコードを書いみると良い。 一番重要なのは、 あとから困ったときに調べるために使うこと 。

読み終わると
- Pythonがかけて嬉しくなる
- エンジニアの仲間に入れてた気がする
STEP3(+α):Courseraのmachine-learning
無料 でここまで使える学習ツールはすごい!
機械学習のロジック部分で、実際にはCourseraを全くやっていなくてもコーディングはできる。知っておくとパラメーターチューニングの意味を理解できる面白い。 通勤中などの移動中に聞ける。 英語できなくても、日本語も用意されているのでほぼ問題ない。
こういう記事からも力をもらいながら、完了。

学習を終えると
- なんか機械学習の理論がわかった気になれる
- ただ、本当にすぐに忘れる
- アンドリュー先生(講師の先生)が優しすぎて好きになる
実際にコーディングもやってみる
PandasとMachineLearning
KaggleのLearnがめちゃくちゃ良い。しかも 無料。 英語だけれど、Google翻訳を使えばほぼ問題なく進められる。
機械学習を実際に行う際のベースとなる部分なので、これはやっておくことをおすすめする。ただ、使わないと忘れるので注意。

本を読みながら深掘りしてみる
pythonで始める機械学習 を読んで、気になるところは写経してみる。
実際のプロジェクトをする際は、機械学習のパラーメーターチューニングなどはディレクターには求められていないと思うので、1章から3章くらいまでやれば十分だと思う。

読み終わると
- 機械学習のコードが書けて、嬉しくなる
- なんか実際のデータでやってみたくなる
(補足)コーディングに利用するツール
自分で環境構築できる方はぜひそちらで。 環境構築ができない/しない方は、GoogleのColaboratoryでやるのがおすすめ。 これも無料で簡単なので、僕もこれを使いました。めっちゃ楽です。
プロジェクト・案件にするまで
はじめに
プロマネとして、機械学習プロジェクトを始めるならこれは必読書です。

本書では、機械学習やデータ分析の道具をどのようにビジネスに生かしていけば良いのか、また不確実性が高いと言われている機械学習プロジェクトの進め方について 整理しています。 本書はもともと、機械学習の初学者向けに書いた文章からはじまりました。入門者のために書きはじ めたのですが、実際には理論を軽めにしたソフトウェアエンジニア向けの実践的なカタログのような形 になっています。 アルゴリズムの話などは他の書籍でも数多く取り上げられているので、本書ではプロジェクトのはじ め方や、システム構成、学習のためのリソースの収集方法など、読者が「実際どうするの?」と気にな るであろう点を中心にしています
とある通り、 プロジェクト始めたいけど、でどうするの? ということが書いてありますので、実施にプロジェクトを進める方にはすごく学びが大きいかと思います。 実際に、「その作業必要?」のようなリソース判断をすることや、全体像を理解することで手戻りを少なくする一助にもなるかと思います。
この要約がわかりやすかったです。
読み終わると
- 機械学習のプロジェクトは思っているよりも多くのことがあるのだと知る
- 実際にプロジェクトをやってみたくなる
実際にやったこと
本書の中で重要だと思ったのは、機械学習を使うことを目的化しないということでした。 機械学習の本なのに、 別に機械学習を使う必要は必ずしもない と書いてあり驚きました。
実際に案件化していくステップとしては、 1.ユーザーの課題を明確にする 2.機械学習を使わずに解決する方法を考える 3.どうしても必要な場合は機械学習を活用する です。
機械学習の有無にかかわらず、 ユーザーの課題を明確にする ことからスタートして、 機械学習を解決策の一つ として持っておく感覚かと思います。
STEP1:ユーザー課題を明らかにする
プロジェクトを進めるにあたり、課題を明確化します。 実際に僕らが進めた場合は、経営陣やビジネスサイドの方と、
1.経営陣が認識している事業課題 2.現状現場が認識しているサービス課題 3.サービス以外にも、現場メンバーの作業に関する課題
など、様々なレイヤーでサービス課題/業務課題に関するディスカッションする機会を取りました。 課題を俯瞰して考えることで、課題理解も広がり、実際モチベーションも上がりました。
このステップを終えると
- やっぱり〇〇はすごい解決したいよね〜(サービスの大きな課題)を再認識できます
- 普段そんな作業をしてるのか。。。という現場のリアルを知れるます
- 他の部署の人と仲良くなります
- 実際にやる前提で話をするので、すごく楽しいです。
STEP2:課題の解決策を考えて、進める
初めて案件を進めるとなれば、どのように案件を進めるかが難しいかと思います。
はじめての機械学習関連のプロジェクトということもあり意識したのは、いかに ライトに着地させて一定の効果を出す かでした。
そのための課題設定と解決策を決めます。
本当は、これが理想。 ただ、簡単に見つからないですよね。。。

実際に進めていくなかで、最初の案件として一番しっくりきたのはこういう施策でした。
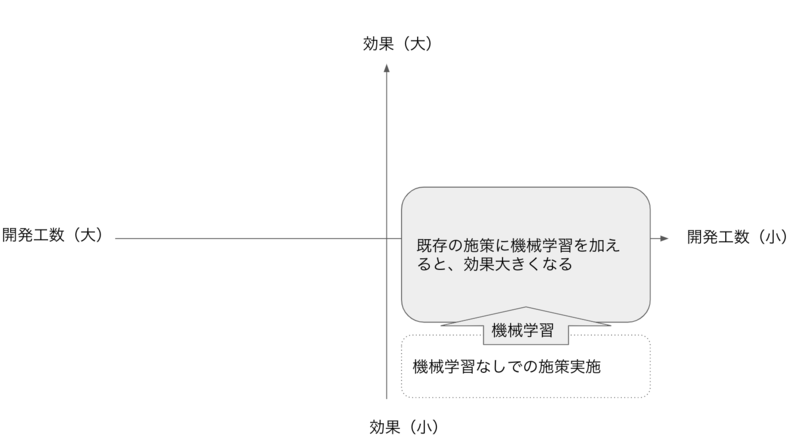
機械学習を取り入れる理由が明確にあり 、且つ工数も比較的小さいもの。 ここを見つけてプロジェクト化していくことで、進みやすくなるかと思います。
実は、ここで言う開発工数とは、機械学習の基盤を作成する工数は除いて考えています。 機械学習の運用基盤を作成するのは工数がもちろん高いので、
- できるだけ使い回せるロジックにすること
- 一度作成すれば、それほどアプリケーション開発の工数が変わらないこと
が重要なので、複数案件化できる状態にしておくことで基盤を作りやすくなるかと思います。
STEP3:巻き込む人を間違えない

前出のまとめ記事にもありましたが、案件を進める上で上記のメンバーは巻き込む必要があります。 そこで間違えると話が進まないので、初めてプロジェクトを進める場合は気にしてみてください。
まとめ/終わりに
ここまでお読みいただきありがとうございました。 はじめての記事でしたが、少しでも参考にしていただければ嬉しい限りです。
- 基本的なインプットから、コーディング、プロジェクト化など一通りやってみて非常に勉強なりました。
- 実際にコーディングもプロジェクトもやってみることが一番だと思いました。
- 案件を考えるときに「機械学習」という選択肢を持てるのは、プロマネとしては強みにな今後なりうるのだろう思います。
- ただ、選択肢の一つということを意識することは重要
- 機械学習を使う!と言いながら、やはりいちばん大切なのは、「ユーザーの課題は何か?」という問いに尽きると改めて思いました。
- 実際に、知見がない中で初めてプロジェクトを進める場合は、関わるメンバーや案件は慎重に進めるとよいと思います。
- 時代の後押しはあるので、比較的会社も挑戦を応援してくれると思います。