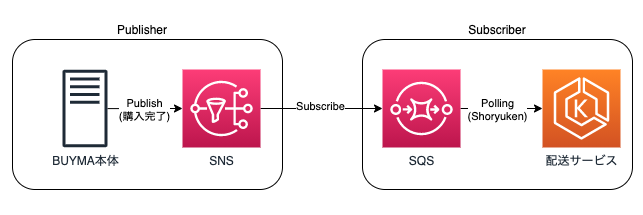
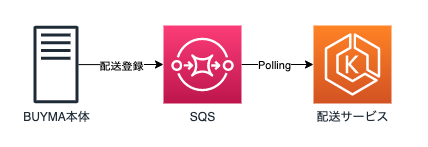
目次
はじめに
コロナ禍の中、皆さんどのようにお過ごしでしょうか。
私はリモートワークを続けてますが、自宅のリモートデスクワーク環境をすぐに整えなかったため、薄いクッションで座りながらローテーブルで3ヶ月経過した頃に身体の節々で悲鳴をあげました。猫背も加速...
さて、エニグモでの仕事も半年以上経過し、データ分析基盤の開発運用保守やBI上でのデータ整備などを対応をさせていただいてますが、今回は社内で利用されているAirflowの同期処理の話をしたいと思います。
尚、こちらの記事を書くにあたり、同環境の過去記事 Enigmo Advent Calendar 2018 がありますので、良ければそちらもご覧ください。
そもそも同期処理とは?
例えば、以下のようなデータ分析基盤上でのETL処理があったとします。
処理1. 連携元DBのあるテーブルをDataLake(GCS)へファイルとして格納後、DWH(BigQuery)へロードする
処理2. DWH上のデータを加工後、外部へCSV連携する
上記の処理は順番に実行されないと必要なデータを含めた抽出ができなくなってしまい、外部へデータ連携できなくなります。そのためには処理1の正常終了確認後に処理2を実施するという、同期処理を意識した実装をする必要があります。
例だとシンプルですが、業務上では徐々にETL処理も増えていき、複雑化していきます。
こうした同期処理は、初めはなくても問題にならないことが多いのですが、徐々に処理遅延が発生してタイミングが合わなくなったり、予期せぬ一部の処理エラーが原因で関連する後続処理が全て意図せぬ状態で動き出してしまったりします。そうならないためにも、設計時点で同期について意識することが大事だと思います。
Airflowによる同期処理
Airflowでは ExternalTaskSensor を使用することで実装可能となります。
Airflowのソース上ではdependという用語が使われているので、Airflowの世界では「同期」ではなく、「依存」と呼んだ方が良いのかもしれません。適弁読み替えていただければ...
では、Airflowでの同期検証用サンプルコードを作成してみましたので、実際に動かしながら検証したいと思います。尚、Airflowバージョンは1.10.10となります。
先ほどのETL処理を例にして、下記の内容で検証してみます。
実際のファイル出力やDBへのロード処理などはここでは割愛して、DummyOperatorに置き換えてます。
処理1. 連携元DBのあるテーブルをDataLake(GCS)へファイルとして格納後、DWH(BigQuery)へロードする
dag_id: sample_db_to_dwh_daily
schedule: 日次16:00
tables: TABLE_DAILY_1, TABLE_DAILY_2, TABLE_DAILY_3
処理2. DWH上のテーブルを用いてデータ加工後、外部ツールへCSV連携する
dag_id: sample_dwh_to_file_daily_for_sync_daily_16
schedule: 日次17:00
tables: TABLE_DAILY_1, TABLE_DAILY_2, TABLE_DAILY_3
検証時のコード
まずは処理1のサンプルコードになります。
from airflow.models import DAG
from datetime import datetime
from airflow.operators.dummy_operator import DummyOperator
dag = DAG(
dag_id='sample_db_to_dwh_daily',
start_date=datetime(2020, 12, 1),
schedule_interval='0 16 * * *'
)
tables = ['TABLE_DAILY_1',
'TABLE_DAILY_2',
'TABLE_DAILY_3'
]
for table_name in tables:
db_to_dwh_operator = DummyOperator(
task_id='db_to_dwh_operator_%s' % table_name,
dag=dag
)
terminal_operator = DummyOperator(
task_id='terminal_operator_%s' % table_name,
dag=dag,
trigger_rule='none_failed'
)
db_to_dwh_operator >> terminal_operator
次に処理2のサンプルコードです。
from airflow.models import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.sensors.external_task_sensor import ExternalTaskSensor
from airflow.utils.state import State
from datetime import datetime, timedelta
tables = ['TABLE_DAILY_1',
'TABLE_DAILY_2',
'TABLE_DAILY_3'
]
def _dwh_to_file_operator(dag,
table_name,
depend_external_dag_id,
depend_external_dag_execution_delta):
dwh_to_file_operator = DummyOperator(
task_id='dwh_to_file_operator_%s' % table_name,
dag=dag
)
sensors = []
sensors.append(ExternalTaskSensor(
task_id='wait_for_sync_db_to_dwh_%s' % table_name,
external_dag_id=depend_external_dag_id,
external_task_id='terminal_operator_%s' % table_name,
execution_delta=depend_external_dag_execution_delta,
allowed_states=[State.SUCCESS, State.SKIPPED],
dag=dag))
for sensor in sensors:
sensor >> dwh_to_file_operator
terminal_operator = DummyOperator(
task_id='terminal_operator_%s' % table_name,
dag=dag,
trigger_rule='none_failed')
dwh_to_file_operator >> terminal_operator
args = {
'start_date': datetime(2020, 12, 3)
}
dag = DAG(
dag_id='sample_dwh_to_file_daily_for_sync_daily',
default_args=args,
schedule_interval='0 17 * * *'
)
for table_name in tables:
_dwh_to_file_operator(
dag=dag,
table_name=table_name,
depend_external_dag_id='sample_db_to_dwh_daily',
depend_external_dag_execution_delta=timedelta(hours=1)
)
サンプルをAirflow画面で見ると?
上記2つのDAGをAirflowのWebUIで見ると以下のようになります。
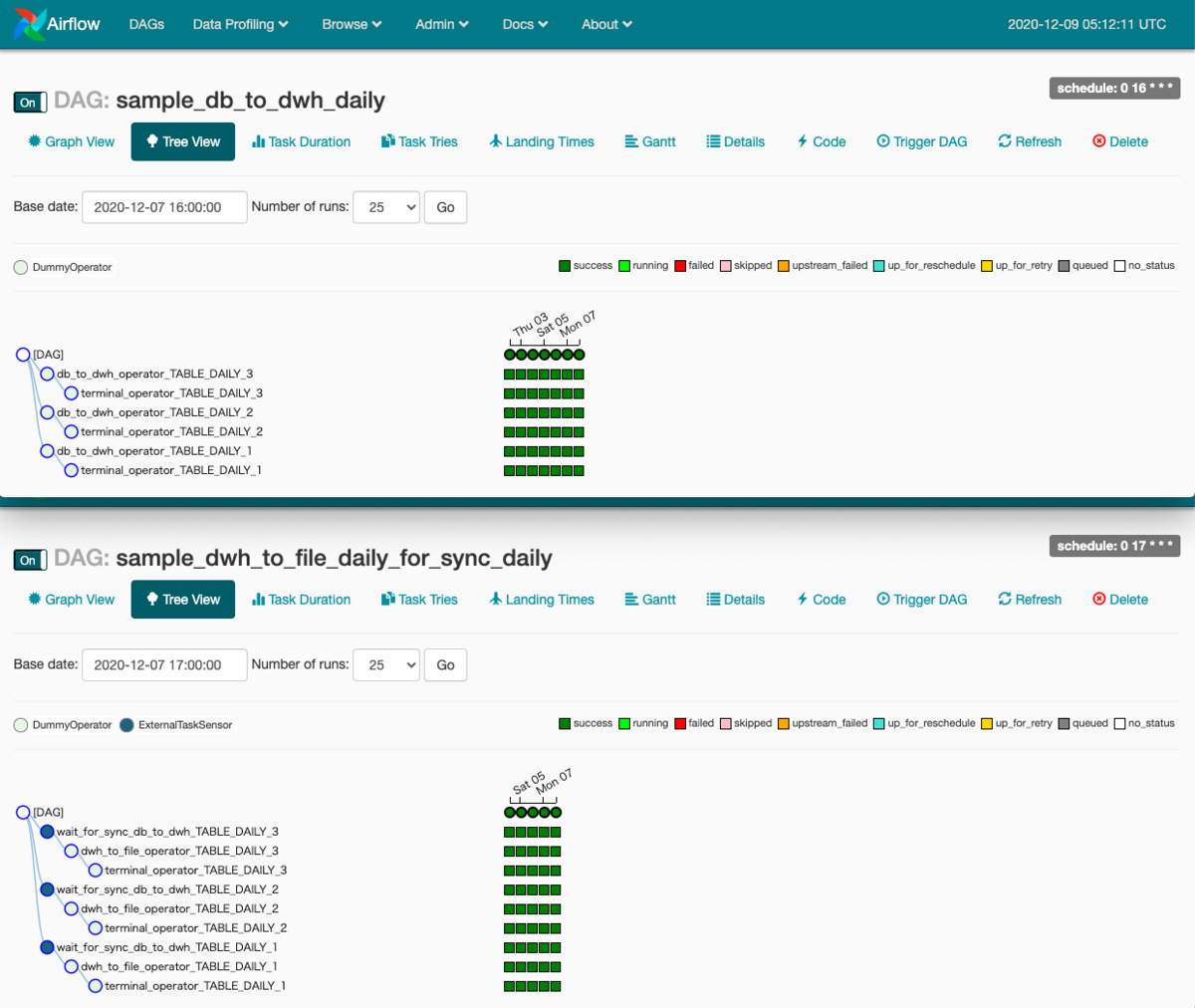
同期処理をするoperatorは「wait_for_sync_db_to_dwh 」です。図でも ExternalTaskSensor のアイコンになってますね。
今回は3テーブルあり、それぞれ並列処理を想定しているため、3つあります。
そして、それぞれ、該当するテーブルのterminal_operator処理完了を確認後、後続処理が実行されます。
では上記の同期処理がAirflowのログでどのように表示されるか見ていきたいと思います。
同期遅延なし時のAirflowログ
まずは、既に sample_db_to_dwh_daily が完了していた場合です。
3テーブル毎のログを載せておきます。
TABLE_DAILY_1
~~
DAG: sample_dwh_to_file_daily_for_sync_daily
Task Instance: wait_for_sync_db_to_dwh_TABLE_DAILY_1 2020-12-07 17:00:00
~~
[2020-12-09 02:00:09,833] {taskinstance.py:669} INFO - Dependencies all met for <TaskInstance: sample_dwh_to_file_daily_for_sync_daily.wait_for_sync_db_to_dwh_TABLE_DAILY_1 2020-12-07T17:00:00+00:00 [queued]>
[2020-12-09 02:00:09,840] {taskinstance.py:669} INFO - Dependencies all met for <TaskInstance: sample_dwh_to_file_daily_for_sync_daily.wait_for_sync_db_to_dwh_TABLE_DAILY_1 2020-12-07T17:00:00+00:00 [queued]>
[2020-12-09 02:00:09,841] {taskinstance.py:879} INFO -
--------------------------------------------------------------------------------
[2020-12-09 02:00:09,841] {taskinstance.py:880} INFO - Starting attempt 1 of 1
[2020-12-09 02:00:09,841] {taskinstance.py:881} INFO -
--------------------------------------------------------------------------------
[2020-12-09 02:00:09,848] {taskinstance.py:900} INFO - Executing <Task(ExternalTaskSensor): wait_for_sync_db_to_dwh_TABLE_DAILY_1> on 2020-12-07T17:00:00+00:00
[2020-12-09 02:00:09,851] {standard_task_runner.py:53} INFO - Started process 48063 to run task
[2020-12-09 02:00:09,905] {logging_mixin.py:112} INFO - Running %s on host %s <TaskInstance: sample_dwh_to_file_daily_for_sync_daily.wait_for_sync_db_to_dwh_TABLE_DAILY_1 2020-12-07T17:00:00+00:00 [running]> ip-123-456-78-910.dokoka_toku.compute.internal
[2020-12-09 02:00:09,919] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_1 on 2020-12-07T16:00:00+00:00 ...
[2020-12-09 02:00:09,921] {base_sensor_operator.py:123} INFO - Success criteria met. Exiting.
[2020-12-09 02:00:09,924] {taskinstance.py:1065} INFO - Marking task as SUCCESS.dag_id=sample_dwh_to_file_daily_for_sync_daily, task_id=wait_for_sync_db_to_dwh_TABLE_DAILY_1, execution_date=20201207T170000, start_date=20201208T170009, end_date=20201208T170009
[2020-12-09 02:00:19,834] {logging_mixin.py:112} INFO - [2020-12-09 02:00:19,834] {local_task_job.py:103} INFO - Task exited with return code 0
TABLE_DAILY_2
~~
DAG: sample_dwh_to_file_daily_for_sync_daily
Task Instance: wait_for_sync_db_to_dwh_TABLE_DAILY_2 2020-12-07 17:00:00
~~
[2020-12-09 02:00:09,831] {taskinstance.py:669} INFO - Dependencies all met for <TaskInstance: sample_dwh_to_file_daily_for_sync_daily.wait_for_sync_db_to_dwh_TABLE_DAILY_2 2020-12-07T17:00:00+00:00 [queued]>
[2020-12-09 02:00:09,839] {taskinstance.py:669} INFO - Dependencies all met for <TaskInstance: sample_dwh_to_file_daily_for_sync_daily.wait_for_sync_db_to_dwh_TABLE_DAILY_2 2020-12-07T17:00:00+00:00 [queued]>
[2020-12-09 02:00:09,839] {taskinstance.py:879} INFO -
--------------------------------------------------------------------------------
[2020-12-09 02:00:09,840] {taskinstance.py:880} INFO - Starting attempt 1 of 1
[2020-12-09 02:00:09,840] {taskinstance.py:881} INFO -
--------------------------------------------------------------------------------
[2020-12-09 02:00:09,846] {taskinstance.py:900} INFO - Executing <Task(ExternalTaskSensor): wait_for_sync_db_to_dwh_TABLE_DAILY_2> on 2020-12-07T17:00:00+00:00
[2020-12-09 02:00:09,848] {standard_task_runner.py:53} INFO - Started process 48062 to run task
[2020-12-09 02:00:09,902] {logging_mixin.py:112} INFO - Running %s on host %s <TaskInstance: sample_dwh_to_file_daily_for_sync_daily.wait_for_sync_db_to_dwh_TABLE_DAILY_2 2020-12-07T17:00:00+00:00 [running]> ip-123-456-78-910.dokoka_toku.compute.internal
[2020-12-09 02:00:09,916] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_2 on 2020-12-07T16:00:00+00:00 ...
[2020-12-09 02:00:09,918] {base_sensor_operator.py:123} INFO - Success criteria met. Exiting.
[2020-12-09 02:00:09,921] {taskinstance.py:1065} INFO - Marking task as SUCCESS.dag_id=sample_dwh_to_file_daily_for_sync_daily, task_id=wait_for_sync_db_to_dwh_TABLE_DAILY_2, execution_date=20201207T170000, start_date=20201208T170009, end_date=20201208T170009
[2020-12-09 02:00:19,832] {logging_mixin.py:112} INFO - [2020-12-09 02:00:19,832] {local_task_job.py:103} INFO - Task exited with return code 0
TABLE_DAILY_3
~~
DAG: sample_dwh_to_file_daily_for_sync_daily
Task Instance: wait_for_sync_db_to_dwh_TABLE_DAILY_3 2020-12-07 17:00:00
~~
[2020-12-09 02:00:09,829] {taskinstance.py:669} INFO - Dependencies all met for <TaskInstance: sample_dwh_to_file_daily_for_sync_daily.wait_for_sync_db_to_dwh_TABLE_DAILY_3 2020-12-07T17:00:00+00:00 [queued]>
[2020-12-09 02:00:09,837] {taskinstance.py:669} INFO - Dependencies all met for <TaskInstance: sample_dwh_to_file_daily_for_sync_daily.wait_for_sync_db_to_dwh_TABLE_DAILY_3 2020-12-07T17:00:00+00:00 [queued]>
[2020-12-09 02:00:09,837] {taskinstance.py:879} INFO -
--------------------------------------------------------------------------------
[2020-12-09 02:00:09,837] {taskinstance.py:880} INFO - Starting attempt 1 of 1
[2020-12-09 02:00:09,837] {taskinstance.py:881} INFO -
--------------------------------------------------------------------------------
[2020-12-09 02:00:09,844] {taskinstance.py:900} INFO - Executing <Task(ExternalTaskSensor): wait_for_sync_db_to_dwh_TABLE_DAILY_3> on 2020-12-07T17:00:00+00:00
[2020-12-09 02:00:09,847] {standard_task_runner.py:53} INFO - Started process 48061 to run task
[2020-12-09 02:00:09,901] {logging_mixin.py:112} INFO - Running %s on host %s <TaskInstance: sample_dwh_to_file_daily_for_sync_daily.wait_for_sync_db_to_dwh_TABLE_DAILY_3 2020-12-07T17:00:00+00:00 [running]> ip-123-456-78-910.dokoka_toku.compute.internal
[2020-12-09 02:00:09,915] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_3 on 2020-12-07T16:00:00+00:00 ...
[2020-12-09 02:00:09,917] {base_sensor_operator.py:123} INFO - Success criteria met. Exiting.
[2020-12-09 02:00:09,920] {taskinstance.py:1065} INFO - Marking task as SUCCESS.dag_id=sample_dwh_to_file_daily_for_sync_daily, task_id=wait_for_sync_db_to_dwh_TABLE_DAILY_3, execution_date=20201207T170000, start_date=20201208T170009, end_date=20201208T170009
[2020-12-09 02:00:19,831] {logging_mixin.py:112} INFO - [2020-12-09 02:00:19,831] {local_task_job.py:103} INFO - Task exited with return code 0
注目して欲しい行は下記となります。
※ 他テーブルのログも同じですので、ここから先は記載を割愛します
[2020-12-09 02:00:09,919] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_1 on 2020-12-07T16:00:00+00:00 ...
これが同期処理のログになります。
今回は既に正常終了していたため、1回の確認しか行われておらず、その後、後続処理も含めて正常終了してることが分かります。
同期遅延あり時のAirflowログ
次に前提のタスクが遅延して正常終了した場合のAirflowログもみていきたいと思います。
~~~
DAG: sample_dwh_to_file_daily_for_sync_daily
Task Instance: wait_for_sync_db_to_dwh_TABLE_DAILY_1 2020-12-08 17:00:00
~~~
[2020-12-10 02:00:04,174] {taskinstance.py:669} INFO - Dependencies all met for <TaskInstance: sample_dwh_to_file_daily_for_sync_daily.wait_for_sync_db_to_dwh_TABLE_DAILY_1 2020-12-08T17:00:00+00:00 [queued]>
[2020-12-10 02:00:04,182] {taskinstance.py:669} INFO - Dependencies all met for <TaskInstance: sample_dwh_to_file_daily_for_sync_daily.wait_for_sync_db_to_dwh_TABLE_DAILY_1 2020-12-08T17:00:00+00:00 [queued]>
[2020-12-10 02:00:04,182] {taskinstance.py:879} INFO -
--------------------------------------------------------------------------------
[2020-12-10 02:00:04,182] {taskinstance.py:880} INFO - Starting attempt 1 of 1
[2020-12-10 02:00:04,182] {taskinstance.py:881} INFO -
--------------------------------------------------------------------------------
[2020-12-10 02:00:04,189] {taskinstance.py:900} INFO - Executing <Task(ExternalTaskSensor): wait_for_sync_db_to_dwh_TABLE_DAILY_1> on 2020-12-08T17:00:00+00:00
[2020-12-10 02:00:04,192] {standard_task_runner.py:53} INFO - Started process 21683 to run task
[2020-12-10 02:00:04,245] {logging_mixin.py:112} INFO - Running %s on host %s <TaskInstance: sample_dwh_to_file_daily_for_sync_daily.wait_for_sync_db_to_dwh_TABLE_DAILY_1 2020-12-08T17:00:00+00:00 [running]> ip-123-456-78-910.dokoka_toku.compute.internal
[2020-12-10 02:00:04,259] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_1 on 2020-12-08T16:00:00+00:00 ...
[2020-12-10 02:01:04,322] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_1 on 2020-12-08T16:00:00+00:00 ...
[2020-12-10 02:02:04,385] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_1 on 2020-12-08T16:00:00+00:00 ...
[2020-12-10 02:03:04,448] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_1 on 2020-12-08T16:00:00+00:00 ...
[2020-12-10 02:04:04,511] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_1 on 2020-12-08T16:00:00+00:00 ...
(省略)
[2020-12-10 10:27:29,163] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_1 on 2020-12-08T16:00:00+00:00 ...
[2020-12-10 10:28:29,226] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_1 on 2020-12-08T16:00:00+00:00 ...
[2020-12-10 10:29:29,273] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_1 on 2020-12-08T16:00:00+00:00 ...
[2020-12-10 10:30:29,298] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_1 on 2020-12-08T16:00:00+00:00 ...
[2020-12-10 10:31:29,360] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_daily.terminal_operator_TABLE_DAILY_1 on 2020-12-08T16:00:00+00:00 ...
[2020-12-10 10:31:29,363] {base_sensor_operator.py:123} INFO - Success criteria met. Exiting.
[2020-12-10 10:31:29,366] {taskinstance.py:1065} INFO - Marking task as SUCCESS.dag_id=sample_dwh_to_file_daily_for_sync_daily, task_id=wait_for_sync_db_to_dwh_TABLE_DAILY_1, execution_date=20201208T170000, start_date=20201209T170004, end_date=20201210T013129
[2020-12-10 10:31:33,698] {logging_mixin.py:112} INFO - [2020-12-10 10:31:33,698] {local_task_job.py:103} INFO - Task exited with return code 0
先ほどのPoking行がログに表示され続けていることが分かります。今回は途中でタスクを手動で動かして正常終了させました。
尚、Pokingの間隔はExternalTaskSensorの引数でpoke_interval
を設定すると変更ができました。ソースを見るとデフォルトは60秒のようです。ログとも一致してますね。
同期タイムアウト時のAirflowログ
業務では非機能要件も大事だと思います。
Airlfowでは、ExternalTaskSensorの引数でtimeoutがあるようです。
こちらでタイムアウト(default: 1週間ですかね、長っ)を適切に設定して、エラー検知をしてみたいと思います。
sample_dwh_to_file_daily_for_sync_hourly/wait_for_sync_db_to_dwh_TABLE_HOURLY_1/2020-12-09T17:00:00+00:00/4.log.
[2020-12-11 18:21:14,539] {taskinstance.py:669} INFO - Dependencies all met for <TaskInstance: sample_dwh_to_file_daily_for_sync_hourly.wait_for_sync_db_to_dwh_TABLE_HOURLY_1 2020-12-09T17:00:00+00:00 [queued]>
[2020-12-11 18:21:14,551] {taskinstance.py:669} INFO - Dependencies all met for <TaskInstance: sample_dwh_to_file_daily_for_sync_hourly.wait_for_sync_db_to_dwh_TABLE_HOURLY_1 2020-12-09T17:00:00+00:00 [queued]>
[2020-12-11 18:21:14,551] {taskinstance.py:879} INFO -
--------------------------------------------------------------------------------
[2020-12-11 18:21:14,551] {taskinstance.py:880} INFO - Starting attempt 4 of 9
[2020-12-11 18:21:14,552] {taskinstance.py:881} INFO -
--------------------------------------------------------------------------------
[2020-12-11 18:21:14,563] {taskinstance.py:900} INFO - Executing <Task(ExternalTaskSensor): wait_for_sync_db_to_dwh_TABLE_HOURLY_1> on 2020-12-09T17:00:00+00:00
[2020-12-11 18:21:14,568] {standard_task_runner.py:53} INFO - Started process 84130 to run task
[2020-12-11 18:21:14,625] {logging_mixin.py:112} INFO - Running %s on host %s <TaskInstance: sample_dwh_to_file_daily_for_sync_hourly.wait_for_sync_db_to_dwh_TABLE_HOURLY_1 2020-12-09T17:00:00+00:00 [running]> ip-123-456-78-910.dokoka_toku.compute.internal
[2020-12-11 18:21:14,639] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_hourly.terminal_operator_TABLE_HOURLY_1 on 2020-12-10T16:00:00+00:00 ...
[2020-12-11 18:22:14,701] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_hourly.terminal_operator_TABLE_HOURLY_1 on 2020-12-10T16:00:00+00:00 ...
[2020-12-11 18:23:14,764] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_hourly.terminal_operator_TABLE_HOURLY_1 on 2020-12-10T16:00:00+00:00 ...
[2020-12-11 18:24:14,828] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_hourly.terminal_operator_TABLE_HOURLY_1 on 2020-12-10T16:00:00+00:00 ...
[2020-12-11 18:25:14,892] {external_task_sensor.py:117} INFO - Poking for sample_db_to_dwh_hourly.terminal_operator_TABLE_HOURLY_1 on 2020-12-10T16:00:00+00:00 ...
[2020-12-11 18:25:14,898] {taskinstance.py:1145} ERROR - Snap. Time is OUT.
Traceback (most recent call last):
File "/opt/airflow/venv/lib/python2.7/site-packages/airflow/models/taskinstance.py", line 983, in _run_raw_task
result = task_copy.execute(context=context)
File "/opt/airflow/venv/lib/python2.7/site-packages/airflow/sensors/base_sensor_operator.py", line 116, in execute
raise AirflowSensorTimeout('Snap. Time is OUT.')
AirflowSensorTimeout: Snap. Time is OUT.
[2020-12-11 18:25:14,899] {taskinstance.py:1202} INFO - Marking task as FAILED.dag_id=sample_dwh_to_file_daily_for_sync_hourly, task_id=wait_for_sync_db_to_dwh_TABLE_HOURLY_1, execution_date=20201209T170000, start_date=20201211T092114, end_date=20201211T092514
[2020-12-11 18:25:15,070] {logging_mixin.py:112} INFO - [2020-12-11 18:25:15,070] {local_task_job.py:103} INFO - Task exited with return code 1
hourlyに変更して実施したログですが、「Snap. Time is OUT.」と良い感じ(?)にエラーとなってくれました。
業務上では、お目にかかりたくないログ内容ですが...
他にも色々あるようですが、この辺りを抑えておけば基本的な使い方は抑えたことになるかと思います。
所感
実際にAirflow同期処理をやってみて思ったのですが、
- 同期を取る対象のoperatorをどれにするか
- 同期を取るoperatorの時刻差はどれだけあるか
- 非機能要件にあったタイムアウト設定で適切にエラーで落とそう
- 複雑になるとDAG間の関係性がわかるグラフをWebUIでサクッとみたい
が、気になりました。
「同期を取る対象のoperator」は「terminal_operator_<テーブル名>」としました。
ダミー処理なので冗長にはなってしまいますが、各並列処理毎に加えておいたほうがDAG修正時の同期影響を意識しなくて良くなるのかなと思ったためです。
また、DummyOperator利用時に 「trigger_rule='none_failed'」の引数を付け加えないと、先に実行されたケースもありましたので注意が必要そうです。
「同期を取るoperatorの時刻差」ですが、何度も繰り返してると混乱してしまう可能性もあるので、テストでも十分に気をつけて対応しないといけないですよ(to自分)。実際の業務でもtimedeltaで指定する時刻に誤りをテストで見落としてしまい、その結果、リリース後に同期処理が想定時間通りに終わらず遅延してしまい、外部連携のタイミングに間に合わなくなり問題になってしまいました...。
今回の検証例は、お互いdaily実行だったのですが、頻度が異なると慎重な対応が求められそうです。
ただ、この辺の制御はAirflowのコアな制御なので、今後、利用者が意識しないで済むようにdag_idとオプション引数で渡したら、同期を取ってくれるような機能があると良いなとも思いました。利用頻度が多くなると、そういった実装も検討しないといけないのかもしれません。
あとは、WebUI上にてDAGの関係性がグラフで見れると、意図したoperatorで同期が取れているかの確認がやりやすいと思いました。
見方が分からないだけなのか、未実装なのか把握できてないのですが、WebUIをみる限り今回のAirflowのバージョン1.10.10ではなさそうです。
最後に
Airflowでの同期処理について少しでも伝わればと思い、このテーマで記事を書いてみました。
本記事を通して少しでもイメージを掴めて頂けますと幸いです。
他にも面白そうな機能はあると思いますので、また、機会があれば投稿したいと思います。
私からは以上となります。最後までお読み頂きありがとうございました。
明日の記事の担当はエンジニアの高山さんです。お楽しみに。
株式会社エニグモ 正社員の求人一覧
hrmos.co