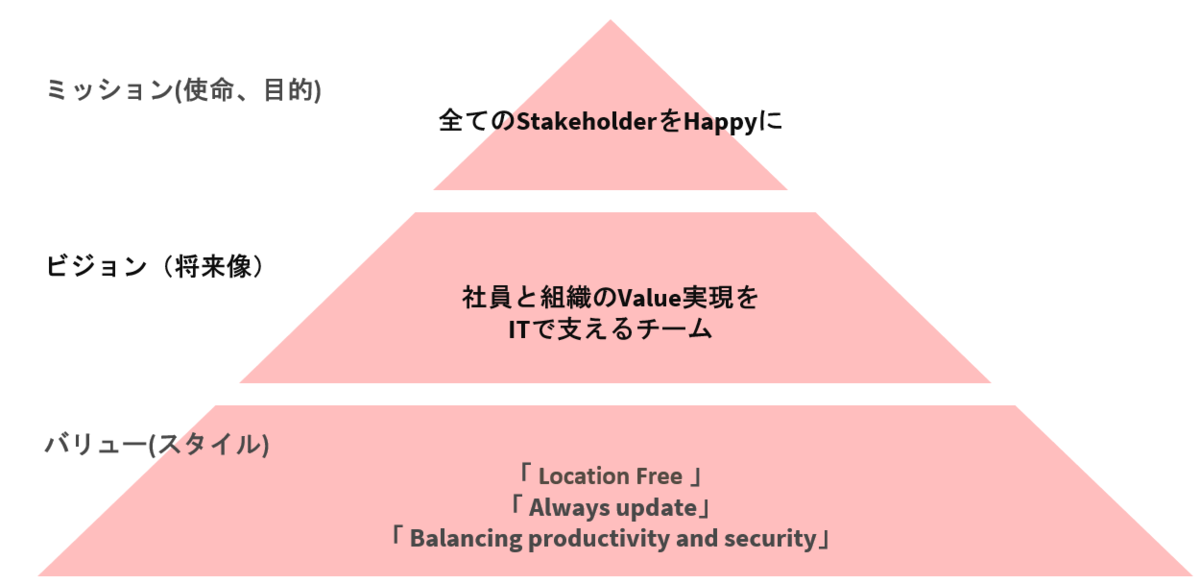
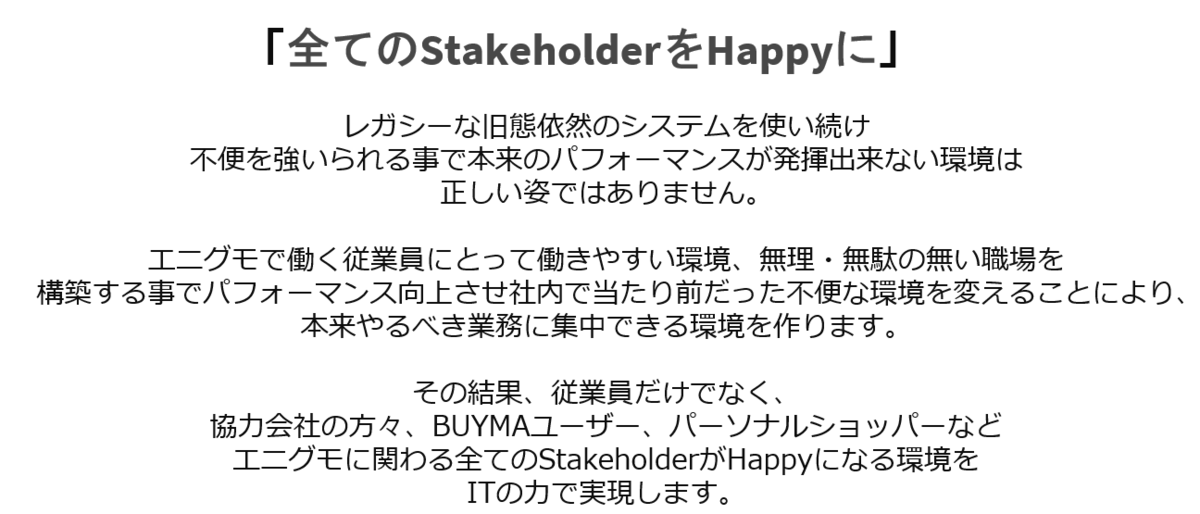
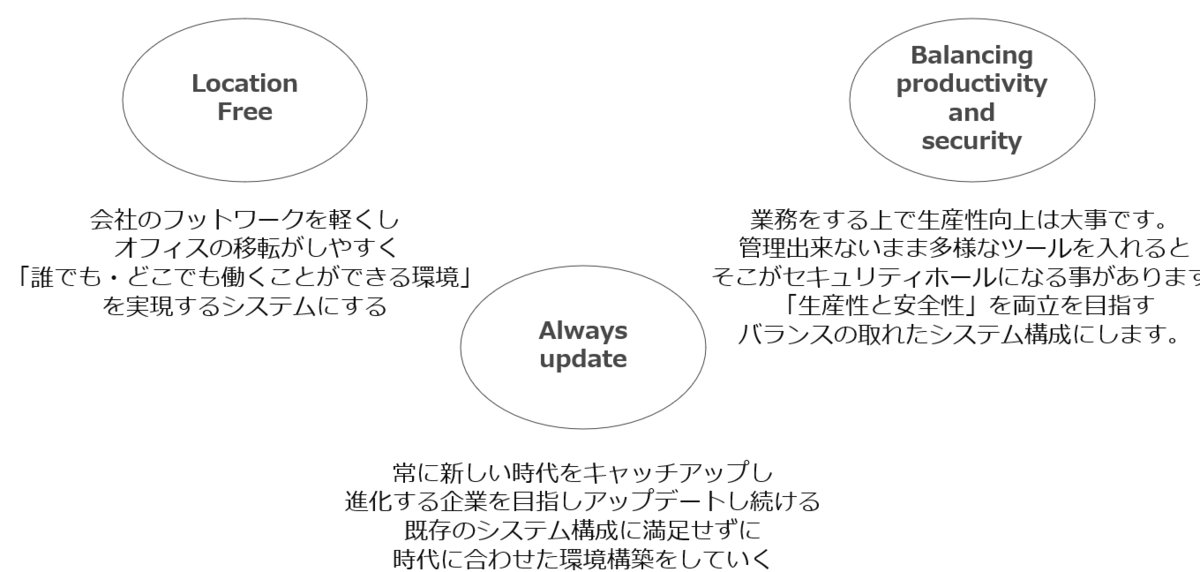
こんにちは、エニグモカスタマーマーケティング事業本部で出品審査などを担当している杉山です。この記事はEnigmo Advent Calendar 2021の10日目の記事です。
昨年のアドベントカレンダーでは、日頃の担当業務についてWantedlyで書きましたが、今回は開発者ブログにお邪魔しました。
エンジニアではなくビジネスサイドの人間ですが、通常業務の傍らITツールを駆使して、ユーザー対応の現場の自動化や効率化などに取り組んでいます。
どうしても手元で作業が必要で、エンジニアに開発してもらうほどではないんだけど、これが自動になったら楽なのに!とかもっと効率よく日々の業務をこなして価値の高い仕事に取り組みたいよー!と思う瞬間がありませんか?私はあります。もう毎日のようにあります。
もちろん大規模な運用改善やシステムの導入などはエンジニアと一緒に開発したほうが圧倒的にいいという案件も多々あるので見極めが必要ですが、ひとまず現場の人間が(ほぼ)ノーコードでいろいろできると、エンジニアのリソースが空くまでのその場を凌いだり、新しいことについて考えて取り組む余裕を作り出すことができます。今回はそんなお話の一つです。
餅は餅屋ですから専門家から見れば拙いやり方をしている面もあるかとは思いますが、そこは何卒多めに見ていただければ幸い。
NPSアンケートのチェック運用をツールの自動連携で効率化する
本日のテーマは、BigQueryのデータをデイリーでAirtableに自動連携して、BUYMAのNPSアンケートチェック業務の効率化をした話を書きたいと思います。
NPS(ネットプロモータースコア)とは、EC事業者にとっては定番ですが、取引が完了したお客様に任意で答えていただいている、BUYMAの顧客のロイヤリティを計測するためのアンケート調査です。
NPSの回答には、BUYMAや出品者様のお取引についての貴重なご意見が詰まっています。エニグモではNPS専用のプロジェクトチームを部門横断で結成し、回答を全てチェック、アクティブサポートや今後の開発・施策の検討に活用させていただいています。
これまでのNPSチェック運用と課題
NPSプロジェクトでは、毎日いただく数百のアンケートすべてに目を通し、気になるものをピックアップして定期MTGで今後の対応を議論しています。チェック作業は曜日ごとにプロジェクトメンバーで分担して行っているのですが、それがなかなか手間のかかる作業となっており、また、チェック対応結果の活用という点でも課題が多くありました。
いままでのやり方
Gmailにデイリーで送られる回答データを確認し、Gmail上に対応ログを残す

課題
- チェックに時間がかかりすぎる
- データに直接チェック結果を書き込むことができないので、気になったポイントなどをメモする場合コピペしてドキュメントを整形する作業を毎回する必要がある
- ピックアップのMTGで決まった対応について、進捗管理がしづらい
- 議論のログがメールにしかないため、対応担当者が手元で別途タスクリストを作ったり情報をメモしておかないといけない
- アンケートに答えていただいた方へご連絡する際に、メールリストの作成をするだけで一苦労
- どのアンケートについてどういった議論が起こり、どんな対応を行ったのか、あとから振り返る手段が限られている
……といった具合に、NPSアンケートを導入した初期から続く古の運用のため、やりづらいポイントが多数ある状態でした。
チェック運用のツールをGmail→Airtableに移行し効率化
そこで、以下の2点について解決すべく、運用改善を行いました。
- アンケートのチェック作業の手間を減らす
- 今後の対応のために過去のデータを参照しやすくする
購入者様がアンケートに回答→メンバーが内容チェック→対応内容を決定しタスクリストを作成→進捗管理→回答者様へのご連絡→過去のピックアップ内容の振り返り、という一連の業務の流れを整理し直して、最小限の手数で作業が完了できるようにします。そのために、チェック作業のツールをGmailからデータベースサービスAirtableに移行することにしました。
Airtableは、一言で言うときれいで賢いスプレッドシートです。表形式のデータを直感的に、かつ自由度高く扱うことができるため、多数のデータをチェックして分類したり、追加の情報を手動でメモして管理したり、ということがGoogle Spreadsheet やExcel以上に簡単に見栄え良くできます。
今回はBigQueryから抽出したNPSアンケートのデータを自動でAirtableに同期し、そこでピックアップ運用を全て完結させるようにしました。やることは単にデータの自動同期なのですが、使用ツールが変わるとチェック作業は劇的にやりやすくなります。
※ 今回の記事ではAirtableの細かい使い方については割愛しますが、使いこなせれば本当に便利すぎるサービスなので、おすすめです!
▼参考記事
脱Excel・スプレッドシート!WebプロジェクトのためのAirtable活用術
使用ツールと自動化の流れ
今回の自動化の流れと使用したツールは以下になります。
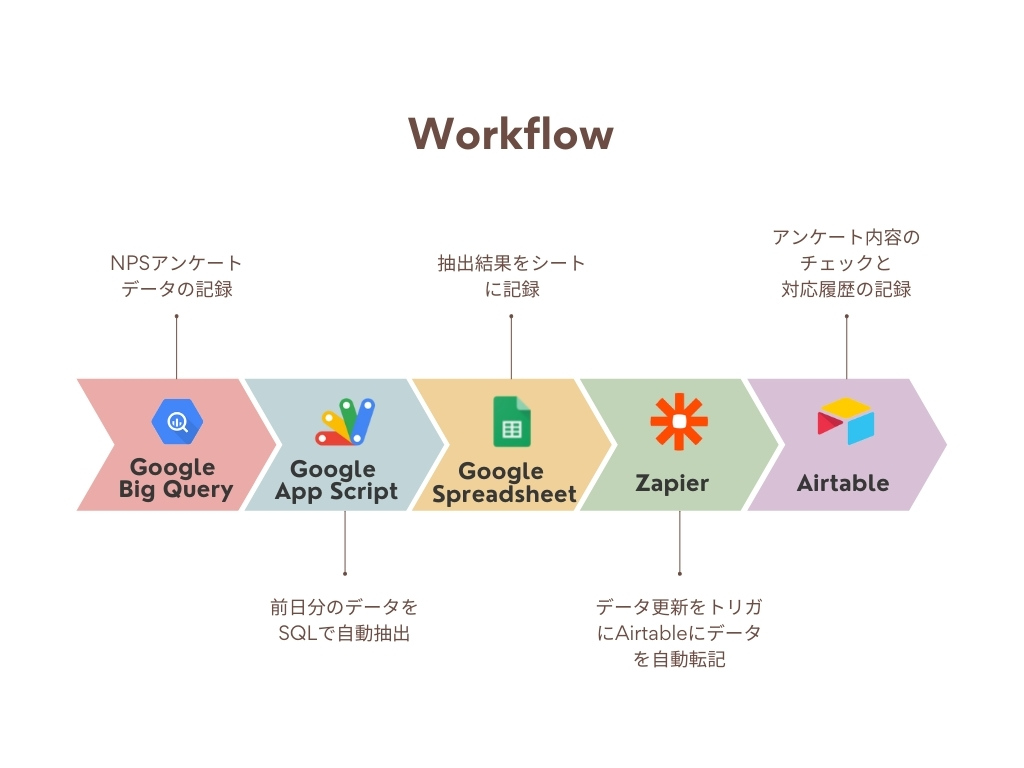
Google BigQuery
NPSアンケートの回答データが溜まっているDB
Google App Script(GAS)
BigQueryから毎日自動でデータ抽出しスプレッドシートに転記するプログラムを作成
Google Spreadsheet
GASで抽出したデータを一時的に溜め、Zapierのトリガーにするために使用
Zapier
複数のWebサービスを組み合わせて独自の自動ワークフローを作成できるタスク自動化ツール。Spreadsheetに同期したデータをトリガーにして、Airtableに自動転記する設定を作成
Aitable
自動同期したデータの目視チェック、対応ログの記録などを行う
GASでBigQueryからデータ抽出してシートに記入
GASを使ってBigQuery上でSQLを動かし、スプレッドシートにデータを転記するまでのコードは以下のような感じです。これは社内の他のGASやググった内容を参考にあれやこれやしてなんとか作りました。GAS、もう数年間書いては忘れを繰り返しているのですが、今回の対応でやっと結構定着した気がします……。
GASは深夜の3時に毎日起動し前日分を取得するようトリガー設定をしています。
//BigQuery var projectNumber = 'データ抽出元の任意のプロジェクトNo'; //スプレッドシート var ss = SpreadsheetApp.getActiveSpreadsheet(); //SQLの結果を出力するシート var sheetNPS = ss.getSheetByName('任意のシート名'); function check() { //処理開始メッセージ Browser.msgBox("処理をしています。しばらくお待ちください。") //SQL結果書き出しシートのクリア sheetNPS.getRange(2, 1,sheetNPS.getLastRow(),sheetNPS.getLastColumn()).clearContent(); // SQLを生成 var sql = "任意のクエリ"; Logger.log(sql); // SQLを実行する準備 var query_results; var resource = { query : sql, timeoutMs: 1000000, // Standard SQLを使用する場合はLegacySqlの使用をfalseにする useLegacySql: false }; try { // SQLを実行 query_results = BigQuery.Jobs.query(resource,projectNumber); } // エラーが発生したらログ出力、メッセージ出力して終了 catch (err) { Logger.log(err); Browser.msgBox(err); return; } while (query_results.getJobComplete() == false) { try { query_results = BigQuery.Jobs.getQueryResults(projectNumber,query_Results.getJobReference().getJobId()); if (query_results.getJobComplete() == false) { Utilities.sleep(3000); //以下の謎のエラーがでたら、この値を増やすか、timeoutMsの値を増やす。「ReferenceError: 「query_Results」が定義されていません。」 } } catch (err) { Logger.log(err); Browser.msgBox(err); return; } } Logger.log(query_results); var resultCount = query_results.getTotalRows(); var resultValues = new Array(resultCount); var tableRows = query_results.getRows(); // 抽出結果を配列(resultValues)に格納 for (var i = 0; i < tableRows.length; i++) { var cols = tableRows[i].getF(); resultValues[i] = new Array(cols.length); for (var j = 0; j < cols.length; j++) { resultValues[i][j] = cols[j].getV(); } } // 配列(resultValues)の内容をシートに出力 sheetNPS.getRange(2,1,resultCount,tableRows[0].getF().length).setValues(resultValues); Browser.msgBox("完了したよ!") //完了メッセージ
Zapierの設定
次に、スプレッドシートのデータ更新をトリガとしてAirtableにデータを転記するZapierを設定します。 当初はGASでそのままAirtableに転記することを想定して作り始めたのですが、AirtableのAPI Documentをよくよく見ると、一度にAPIで追加できるレコードは10まで、という制限があり、数百行を一気に追加したかったため間にZapを挟むことにしました。



これでトリガー設定は完了です。
次に、Airtableに転記をするための設定をします。





これで、毎日前日分のデータをAirtableに自動同期することができます!!
Zapierのトリガ数の上限を解除する
と、うまくいったかと思いきや、運用開始してみたら問題が発生。
Zapierは動作したトリガ数に応じて課金されていく仕組みなので、誤作動防止のために一度に動くトリガが100件を超えると自動でストップする仕様になっていました。今回作ったZapは毎日数百件ある更新データをひとつひとつトリガとしてZapを動かす設定のため、動かすたびに毎回Zapが止まってしまいました。一時停止したZapはボタンひとつで再開作業をすれば問題なく動くのですが、毎朝対応が必要になるのでこれでは自動化の良さが半減してしまいます。
最初は解決方法がわからず、毎日再開をするひと手間をしばらく続けていたのですが、やっぱりめんどくさい!!
Zapierに問い合わせてみると、トリガ上限を上げてもらえることが判明。リミットを500に設定してもらい、無事に完全自動化することに成功しました。
よく調べるとトラブルシューティングにも該当の内容がありました。サポートはすべて英語なので該当箇所を見つけるのも一苦労ですね……。
新・チェック運用
毎日のデータをAirtableに連携することで、フィルター機能で自由に表示を操作することができるようになったので、アンケートのチェック運用もAirtable上でスムーズに行えるようになりました。 まずは、曜日ごとに分担してチェックをしているため、回答を担当曜日ごとに表示できるようそれぞれのViewを作成。

担当曜日の回答に目を通して気になるものにはチェックマークをつけていき、コメント欄にメモを記入するだけでピックアップは終了です。
MTGではチェックがついたものについて確認して議論し、決まった対応内容を購入者様・出品者様それぞれの該当欄に記入して対応の進捗や担当者もここで管理します。

更に、回答いただいたお客様へのご連絡のためのリストもAirtable上のViewで管理できるため、改めてデータ出しをする作業もなくなりました。

運用変更の結果、実現したこと
今回のツールの変更と自動化で、課題だった以下の点について解決し、かなりの効率化を実現することができました。
- MTG前のピックアップのための所要時間が削減でき、1日分のチェックに以前は1時間前後かかっていたものを30分程度でできるようになった
- MTG中にチェックしたものがそのまま対応のタスクリストになるため、進捗が管理しやすくなり対応時間の削減と対応漏れの防止ができた
- 過去に出てきた類似案件の対応見直しや、特定の出品者様・購入者様に過去どういったご意見が多いかをMTG中にさっと参照することができるようになったため、以前よりも的確なフォローが可能になった
- 回答者様への一斉連絡のためのメールリスト抽出が自動で完了できるようになり、手動でリストを作成する手間がなくなった
今後の展望
今回の一番の目的だった業務の効率化は十分に達成することができた一方で、データ活用という観点ではまだまだやれることがあると考えています。
現在は個別のアンケートへの対応のみに活用されていますが、ピックアップしたデータを再度データベース内の他の情報と組み合わせてより高度な分析の材料としたり、特定の回答内容の方にのみMDツールと連携して自動でご案内をしたり、などデータが整ったことで活用の幅を広げることができるはず。貴重なお客様の声をサービス改善に繋げるべく、今後も試行錯誤を続けていきたいと思います。
明日の記事の担当は人事総務グループの右川さんです。お楽しみに!
株式会社エニグモ すべての求人一覧