こんにちは、エニグモ 嘉松です。
この記事はEnigmo Advent Calendar 2021 の17日目の記事です。
はじめに
毎日毎日、それこそ仕事で使わない日は無いくらい、いつもお世話になっている表計算 ソフト。
昔はみんなExcel を使っていましたが、最近は社内でもGoogle スプレッドシート を使うことが増えているように感じます。
(因みに私はLotus 1-2-3 やNumbersは使ったこと無いです。)
さて、皆さんいろいろな関数を駆使して作業を効率化していることかと思います。
代表的な関数をいくつか紹介すると、
SUM
表計算 ソフトの関数の代表格といえば何と言ってもSUMですかね。指定した範囲の合計値を求めてくれます。
「=SUM(A1:A10)」といった形で、合計したいセルの範囲を指定してあげます。
COUNTIF
条件に一致するデータの個数を求めてくれます。
シンタックス はCOUNTIF(範囲, 検索条件)です。「=COUNTIF(A1:A10, "<100")」といった形で、検索の対象とする範囲と、検索する条件を指定します。
結果としては条件に合致したセルの数を返します。
実は私、ほとんど使ったことないですが、よく聞くので紹介しました。
VLOOKUP
VLOOKUPを使えると表計算 ソフトのスキルは中級くらいのレベルになりますかね。
この関数はホントに便利です。もはや無いと生きていけないレベル。
シンタックス はVLOOKUP(検索値, 範囲, 列番号, 検索方法)です。範囲で指定した先頭の列を上から順に検索して検索値に一致する値を探します。見つかったセルと同じ行の列番号にあるセルの値を結果として返します。検索方法はFALSEしか使ったことないです。
ちなみに、Google スプレッドシート の関数の一覧はこちら。
Google スプレッドシートの関数リスト - ドキュメント エディタ ヘルプ
何十、何百の関数が用意されていて、使ったことも無い関数が殆どなのですが、自作のオリジナル関数を作ることも出来ます。
えっ、関数を自分で作る?そんな事できるの?と思われた方も多いかとも思いますが、私も最近知りました(笑)
では、これからオリジナル関数を自作する方法を紹介します。
消費税を求めるオリジナル関数を作ってみる
オリジナル関数、どう作るか?
そのためにはGoogle Apps Scriptでスクリプト を書く必要があります。
Google Apps Script(GAS)とは、Google が開発・提供しているプログラミング言語 です。
JavaScript をベースに開発されたそうです。
Google スプレッドシート を開いたら、タブから「拡張機能 」>「Apps Script」を押下します。
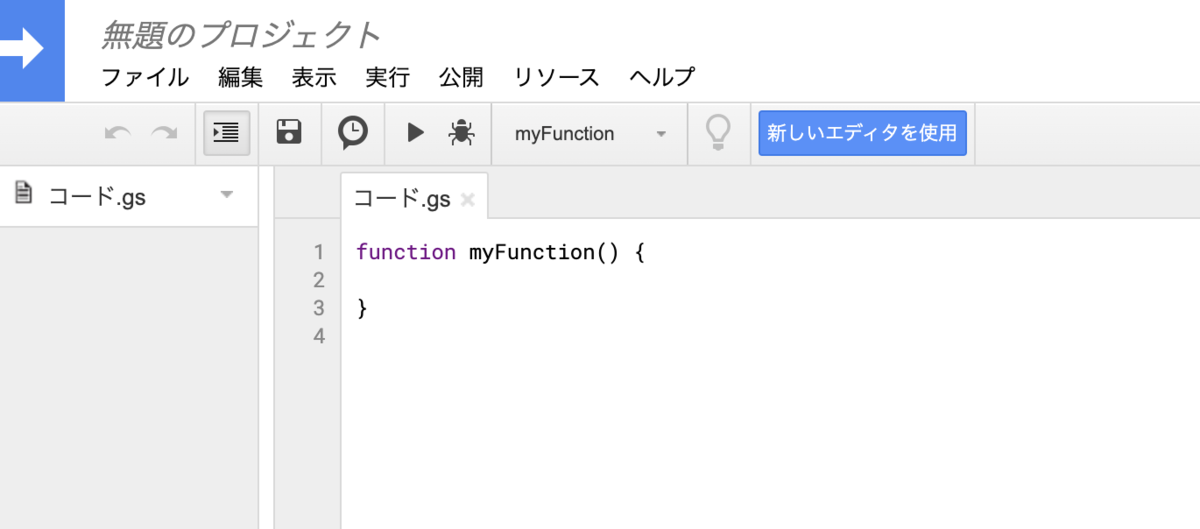
スクリプト エディタを起動
新しいタブが追加されて、以下のようなスクリプト エディタが起動されます。
スクリプト エディタが起動
スクリプト エディタが起動されたら、ここにオリジナル関数のスクリプト を書きます。
ここでは消費税を求める関数myTAX関数を作ってみます。
/* 消費税を返す関数myTAX */
function myTAX(price){
const taxRate = 0.1; //消費税率
return price * taxRate;
}
functionのあとのmyTAXは関数の名前です。
priceは、関数の引数です。この関数の引数は1つなので、このように指定します。
const taxRate = 0.1; //消費税率はtaxRateという定数を作成して、税率の0.1(10%)を代入してあげます。
そしてreturn price * taxRate;で引数で指定されたpriceに消費税率taxRateを掛けて、その結果をreturnで返してあげます。
スクリプト ができたら、フロッピーディスク のアイコンをクリックして保存してあげます。
(いまの若い方はフロッピーディスク なんて知らないと思いますが、これでイメージ付くのかな?)
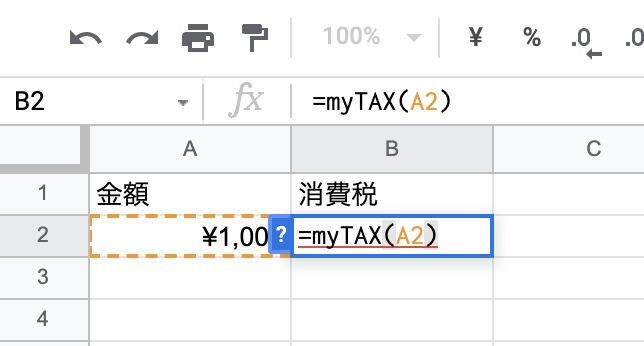
オリジナル関数の使い方
では、作った関数を使ってみましょう。
使い方は簡単で、標準の関数と同様に=の後に関数の名前と引数を指定するだけです。
オリジナル関数の使い方
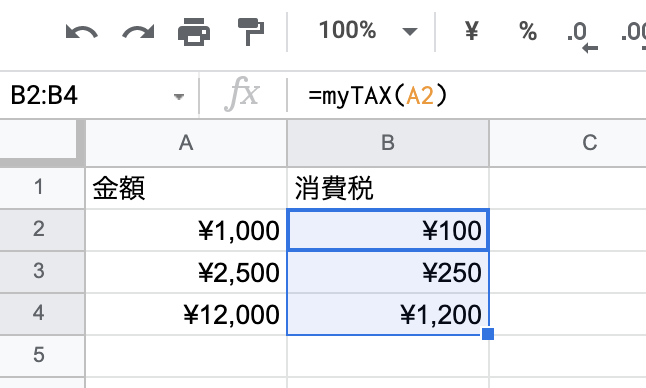
はい、このように消費税の金額が求められました。
オリジナル関数の結果
B2のセルの右下の小さな四角を下に引っ張れば、B2のセルがコピーされて、下の行の消費税が算出されます。
関数のコピー
消費税の算出だけであれば、セルに直接=A2 * 0.1とすればできます。
ただ、オリジナル関数を作って消費税を算出するメリットは、消費税の税率が変わった時にスクリプト の消費税率を変えてあげるだけで、変更後の消費税が取得できます。
const taxRate = 0.12; //消費税率
こんな感じですね。
ABテストの信頼度を算出するオリジナル関数を作ってみた
実は、というか当然ですが私は消費税を算出するオリジナル関数を作りたかったわけではありません。
我々は日常的にABテストを実施しています。
例えばクーポンを配布した時に、配布したグループと配布しなかったグループで注文率に差があるが、どの程度差がでるか、クーポンを配布することで注文は増えるけど利益はどうなのか?といったようなことです。
この時、以下のような結果が出たとしましょう。
ABテストではクーポンの配布を実施したグループをトリートメントグループ、クーポンの効果を検証するために敢えてクーポンを配布しないグループをコントロール グループと呼びます。
対象者
注文者
注文率
トリートメントグループ
179,120
1,677
0.94%
コントロール グループ
11,800
98
0.83%
この結果からクーポンを配布したトリートメントグループの注文率が0.94%とコントロール グループの0.83%を上回っているので「クーポンの効果があった」と判断したくなります。
ただ、世の中、誤差は付き物です。
サイコロを10回振った時に1が10回連続で出たとしても、必ずしもそのサイコロがイカ サマとは決めつけられません。偶然10回連続で1が出る確率は少なからずあります。
同様にクーポンのABテストでも偶然トリートメントグループの注文率が高かった、ということは無くはないです。
そんな事言ったらABテストを行う意味がないではないか、というとそうではありません。
今回の結果が偶然なのか、それとも偶然ではないのかを統計的な手法を使って判断することが可能です。
その方法を統計の用語で検定と呼びます。
検定の方法はいくつかあるのですが、今回はカイ二乗検定 という検定方法を使って検定を行います。
詳細は省略しますがカイ二乗検定 の方法は、以下の順序で行います。
①実績値を集計
注文あり
注文なし
合計
トリートメントグループ
1,677
177,443
179,120
コントロール グループ
98
11,702
11,800
合計
1,775
189,145
190,920
②期待値を算出
注文あり
注文なし
合計
トリートメントグループ
1,665
177,455
179,120
コントールグループ
110
11,690
11,800
合計
1,775
189,145
190,920
③実績値と期待度数の乖離値を求める
④乖離値を合算してカイ二乗 値を求める
⑤カイ二乗 値からp値を求める
⑥p値から有意差を求める
一般的に有意差が95%を超えると有意な差がある、つまり偶然ではないと判断します。
このように有意差を求めるには多くの手順が必要となります。
そこでオリジナル関数の出番です。
今回は①〜④のカイ二乗 検値を求めるところまでをオリジナル関数で行い、⑤〜⑥は標準で用意されている関数を使いました。
function myGETCHISQ(a, b, c, d){
// 実績値
var o = [
a - b,
b,
c - d,
d,
];
var s = o[0]+o[1]+o[2]+o[3];
// 期待値
var e = [
(o[0]+o[1]) * (o[0]+o[2]) / s,
(o[0]+o[1]) * (o[1]+o[3]) / s,
(o[2]+o[3]) * (o[0]+o[2]) / s,
(o[2]+o[3]) * (o[1]+o[3]) / s,
];
// カイ二乗検値
var chisq = 0;
for (i=0; i<=3; i++){
chisq += (o[i] - e[i]) * (o[i] - e[i]) / e[i];
}
return chisq;
}
この関数のシンタックス は、以下のとおりです。
myGETCHISQ(試行回数A, 注文数A, 試行回数B, 注文数B)
上記の例だと、
=myGETCHISQ(179120, 1665, 11800, 98)
となります。もちろん引数にはセルの値を参照させることもできますよ。
この関数で求められたカイ二乗 検値を標準で用意されているCHISQ.DIST.RT関数に与えてあげることでp値が求められます。
CHISQ.DIST.RT(カイ二乗 値, 自由度)
そして、1からp値を引いて100を掛けてあげれば有意差が求まります。
因みにこの例の有意差は75.36%で95%を下回っているので、有意な差が出ているとは言えない、となります。
最後に
今回はGoogle Apps Script(GAS)を使ってGoogle スプレッドシート のオリジナル関数を作る方法を紹介しました。
また、より実践的な例としてABテストの信頼度を算出するオリジナル関数を作ってみました。
GASを使うと日頃の作業を上手に、そして簡単に効率化することが出来ます。
是非参考にしていただければと思います。
明日の記事の担当はデザイナーの本田さんです。お楽しみに。
株式会社エニグモ すべての求人一覧
hrmos.co