こんにちは、データサイエンティストの堀部です。
この記事はEnigmo Advent Calendar 2022の16日目の記事です。
普段の業務では情報検索(検索/レコメンド)、不正検知、ユーザー属性の推定などをBUYMAにプロダクトとして組み込むことを行っています。その中でもモデリング以前のタスク設計や探索的データ分析(EDA: Explanatory Data Analysis)、データのクレンジング・前処理、特徴量エンジニアリングなどを主にSQL(BigQuery)で行う部分に多くの時間を割いています。1
今回は、違和感のある予測結果から気づいた傾向を元にデータの前処理を追加したことでモデルの精度改善につながった一例を紹介いたします。
概要
データから機械的な(ボットのような)アクセスを除外したことで、機械学習モデルの精度が改善しました。 そもそも気づいた経緯や検出方法、除外した結果について紹介いたします。
気づいた経緯
商品のブランドのitem2vecを閲覧履歴から生成した際に、BUYMA内で人気のブランドと直近1年で1件も購入されていないマイナーなブランドの類似度が非常に高く出ているパターンが複数見受けられました。違和感を感じ、学習データでマイナーなブランドに対してアクションを行なっているユーザーのlogを閲覧数が多い順に見たところ、一定間隔で別の商品詳細に遷移するというのを繰り返しているlogが見受けられ、人間ではないアクセスの可能性が高いと判断しました。
ちなみに、item2vecなどのベクトルはarray型でBigQueryに格納し、コサイン類似度などをSQLで計算できる様にしていますがとても便利です。
create temp function cos_sim(vec1 array<float64>, vec2 array<float64>) returns float64 as ( ( select sum(elem1 * elem2) / sqrt(sum(elem1 * elem1))/ sqrt(sum(elem2 * elem2)) from unnest(vec1) elem1 with offset pos1 inner join unnest(vec2) elem2 with offset pos2 on pos1 = pos2 ) );
検出方法
「1度でも1分以内に次の商品詳細への遷移を100回以上繰り返しているユーザー」という条件で検出しました。2こちらをSQLでセッショナイズを行うことで実装しました。3
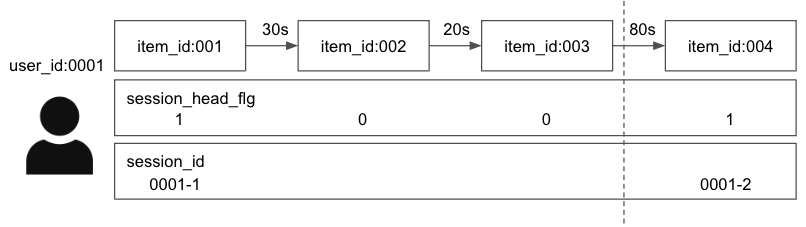
サンプルクエリ
with item_action_view_detail as( select ial.user_id, ial.time, ial.time - lag(ial.time) over ( partition by ial.id order by ial.time ) as interval_action from item_action_log as ial where ial.action = "view_detail" ), session_head as( select id, time, case when lag(time) over ( partition by user_id order by time ) is null then 1 when time - lag(time) over ( partition by user_id order by time ) > interval 60 second then 1 else 0 end as session_head_flg from item_action_view_detail ), session as( select user_id, time, concat( user_id, "-", sum(session_head_flg) over ( partition by user_id order by time rows between unbounded preceding and current row ) ) as session_id, from session_head ), session_summary as ( select session_id, user_id, count(1) as cnt_view, from session group by 1,2 ) select distinct user_id from session_summary where cnt_view >= 100
結果
ランキング学習を行っているモデルに対し、検出したユーザーIDを除外する前と除外した後のデータそれぞれ学習させたモデルでのテストデータでの精度を比較したところMAP(Mean Average Precision)が約2%改善しました。商品のブランドのitem2vecも除外後のデータで生成し直したところ、直感に合うようなブランド同士が類似度が高く出るようになりました。
機械学習での推論結果をBigQueryに格納しているため、MAPなどの評価指標もSQLで計算できるようにしています。 (下記、average_precisionの平均をとったものがMAPになります)
create temp function precision(y_true array<int64>, y_pred array<int64>, n int64) returns float64 as ( ( select sum(case when elem1 = elem2 then 1 else 0 end) / n from unnest(y_true) elem1 with offset pos1, unnest(y_pred) elem2 with offset pos2 where pos2 < n ) ); create temp function average_precision(y_true array<int64>, y_pred array<int64>, n int64) returns float64 as ( ( select sum(precision(y_true, y_pred, m+1)) / array_length(y_true) from unnest(generate_array(0, n-1)) as m where y_pred[safe_offset(m)] in unnest(y_true) ) );
まとめ
やったことは単純ですが、データの前処理の大切さを体感できた事例だったので紹介させていただきました。 Garbage In, Garbage Outを胸に刻みましょう。
おまけ
最近話題のchatGPTにBUYMAについて歌詞を書いてもらいました
手にしたいものを 思い浮かべたら BUYMAに行くよ みんなの想いが集まる 世界中の商品が たくさん見つかるよ お求めやすい価格で 今日も新しいものが届くよ ハイブランドの服や靴 おしゃれなバッグやアクセサリー 雑貨や家電まで BUYMAで探してみよう 会員登録すれば さらにお得な特典が たくさんあるよ お気に入りを見つけて 買い物の楽しみを増やそう BUYMAで楽しい買い物 手にしたいものを 思い浮かべたら BUYMAに行くよ みんなの想いが集まる 今すぐBUYMAで 買い物しよう!
宣伝上手ですね。 話題のAIに弊社のサービスを認知されていて少し嬉しかったです。
明日の記事の担当は人事の右川さんです。お楽しみに。
株式会社エニグモ すべての求人一覧
- データクレンジング〜特徴量生成部分でdbtの活用を検討中です↩
- 実際のSQLではユーザーエージェント(UA)でのボット除外を行ったデータに対して処理しています↩
- SQLでのセッショナイズは、10年戦えるデータ分析入門やビッグデータ分析・活用のためのSQLレシピに詳しく記載されています↩