こんにちは、エニグモでデータアナリストをしている井原です。
この記事は Enigmo Advent Calendar 2021 の 7日目の記事です。
今日は、実際に業務で、データ分析をした内容を元に、データアナリストがどのような仕事をしているのかをお話したいと思います。
データアナリストの仕事
世の中では、データアナリストと言われる職種の仕事は多岐に渡ると思います。
データマイニング、データ分析基盤の整備、ビジュアライゼーション、KPIの設計、機械学習モデルの構築、etc...
エンジニアリングやサイエンスの領域と思われるところを担っているデータアナリストの方もいらっしゃるのではないかと思います。
エニグモの場合、データサイエンティストやデータ基盤エンジニアといった、専門家が在籍しています。そのため、データアナリストは、施策の効果検証やサイト上の課題発見といった、ビジネス領域の課題に対して、データ分析で解を出す仕事にフォーカスすることが多いです。
また、エニグモは、データ分析のリテラシーが高く、データアナリストではないディレクターといった職種の人でも、SQLを回して、データの抽出/分析を行うことが普通の文化になっています。
データアナリストとしては、データ分析の設計や手法を深く理解して、アウトプットを出していくことのやりがいを感じながら、仕事の出来る環境になっていると思います。
決定木による売れ筋商品の分析
ここからは、実際に分析した例を元にして、分析手法として使用した決定木分析について、お話したいと思います。
課題
エニグモが運営しているBUYMAでは、CtoCの売買を仲介するプラットフォームビジネスを行っています。
そのため、ECサイトとして、購入者だけではなく、販売を行う出品者に対してのフォローも行うことが必要です。出品者の方に良質な商品を出品していただくことで、売り場としての魅力が向上し、購入者にとっても、良質なサイトになっていくと考えられます。
しかし、良質な商品とは何なのか?想像するものは、人それぞれで異なると思います。そこを、定性的な感覚だけでなく、定量的なデータ分析を行うことで、売り場にあるべき商品を定義し、出品者の方に出品促進を行っていきたい、というのが、今回の課題でした。
分析方法の選定
良質さを決める要素は数多くあると思いますが、今回はまず、基礎的な分析として、商品のブランド、カテゴリ、モデル名の中で、どのような商品が売れているのかを調査しました。また、売れている商品、の定義については、ビジネス側のメンバーと議論のうえ、CVR(出品された商品数のうち、販売された商品数の割合)としました。
早速、日別のデータを取得し、BUYMAの中で主流となるジャケットカテゴリに絞ると、以下のようなデータが確認できます。
※なお、記事内で取り扱っているデータについては、全て、ダミーデータとなります。
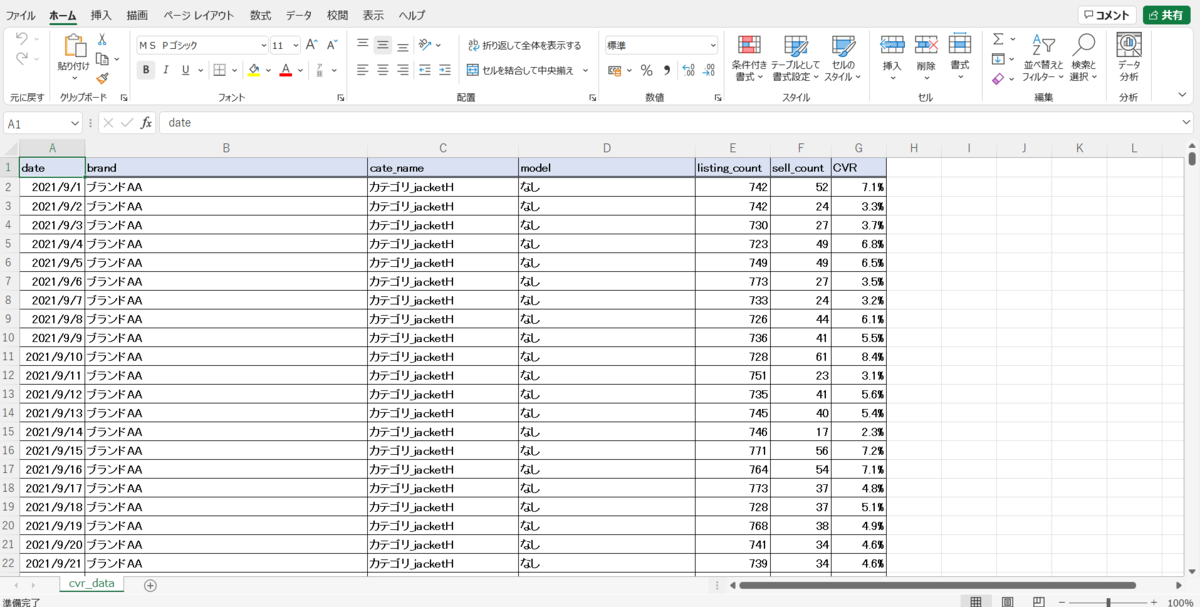
BUYMAで取り扱われているブランド、カテゴリ、モデル名は、数が多く、クロス集計などで解釈することは困難と思われます。
ブランド、カテゴリ、モデル名をそれぞれ単体で集計することも可能ですが、その場合、あるブランドのCVRが高いと、どのようなカテゴリ、モデルでも高いのか?といった解釈が難しくなります。
今回は、CVRに対して、ブランド、カテゴリ、モデル名といった特徴のうち、どの要素の影響が大きいのか?を分析したいですので、可視性が高く、解釈性のよい決定木分析を使って、分析してみることにしました。影響の大きさを見るには、重回帰分析といった手法もありますが、決定木分析であれば、要素の掛け算(このブランドのこのモデルのCVRが高い、といった見方)も確認できます。
※厳密には、重回帰分析でも要素の掛け算を変数とすることで、出来ないことはありませんが。
実装
pythonを使って、実装していきます。
先ほど取得してきたデータのうち、ブランド、カテゴリ、モデル名、を説明変数とし、CVRを目的変数として予測する決定木モデルを作成します。
環境:
Windows 10 Pro
Python 3.9.9
1.ライブラリのimport
必要なライブラリをインポートします。
import pandas as pd import subprocess # 可視化を行うためのライブラリ import matplotlib.pyplot as plt # 回帰の決定木モデルを作成するためのライブラリ from sklearn.tree import DecisionTreeRegressor, export_graphviz from sklearn.model_selection import train_test_split from sklearn.metrics import r2_score from sklearn.metrics import mean_absolute_error
2.データの読み込み
pandasでデータを読み込みます。
df = pd.read_excel("cvr_data.xlsx")[["date", "brand", "cate_name", "model", "listing_count", "sell_count"]] # 必要な列に絞る # データの確認 print(df.head()) print(df.columns)
3.移動平均に変換する
ECデータの場合、平日より休日の方が多く売れる傾向がありますので、7日間移動平均に変換して、データを均します。
ローデータは、前の要素の9/30の次に次の要素の9/1が来てしまうため、9/7以降のデータに絞り込みます。
※もっとよいやり方がありそうな気がしますが、自分の知識だとこうなりました。
df["listing_count"] = df["listing_count"].rolling(7).mean() df["sell_count"] = df["sell_count"].rolling(7).mean() df = df[df["date"] >= "2021-09-07"] # データの確認 print(df.head(30)) # CVRを計算して、カラムを追加 df["cvr"] = df["sell_count"]/df["listing_count"]
4.変数をダミー変数に変換
今回、使用する予測変数は、全て質的データになるので、そのまま、決定木分析に使用することは、出来ません。
get_dummies関数を使って、ダミー変数に変換します。
df = pd.get_dummies(df, drop_first=True) # 2の時点と異なることを確認 print(df.columns)
5.データの分割
予測変数と目的変数、学習用データとテスト用データに分割します。
今回は、モデルの精度を上げることは目的としていないため、テストデータは少なくして、ほとんどのデータを学習データにしました。
exclusion_list = ["cvr", "date", "listing_count", "sell_count"] include_list = [column for column in df.columns if column not in exclusion_list] obj_df = df["cvr"] exp_df = df[include_list] obj_array = obj_df.values exp_array = exp_df.values X_train, X_test, Y_train, Y_test = train_test_split(exp_array, obj_array, test_size=0.01, random_state=222)
6. 決定木モデルの学習
作成したデータで、決定木モデルを学習させます。
# モデルのインスタンス生成 reg = DecisionTreeRegressor(max_leaf_nodes=20) # 学習によりモデル生成 model = reg.fit(X_train, Y_train) print(model) # 評価 y_true = Y_test y_pred = model.predict(X_test) print(r2_score(y_true, y_pred)) print(mean_absolute_error(y_true, y_pred))
7. 木構造を画像に保存
モデルの木構造を解釈できるよう、画像に変換します。
dot_data = export_graphviz(model,
out_file="cvr_data.1.dot",
filled=True,
rounded=True,
feature_names=exp_df.columns
)
subprocess.run("dot -Kdot -Tjpg -Nfontname='MS Gothic' -Efontname='MS Gothic' -Gfontname='MS Gothic' cvr_data.1.dot -o cvr_data.jpg".split()) # 日本語を含むと、文字化けするため、fontを指定
解釈
以上のソースコードを実行すると、以下のような決定木のjpgファイルが出来上がります。
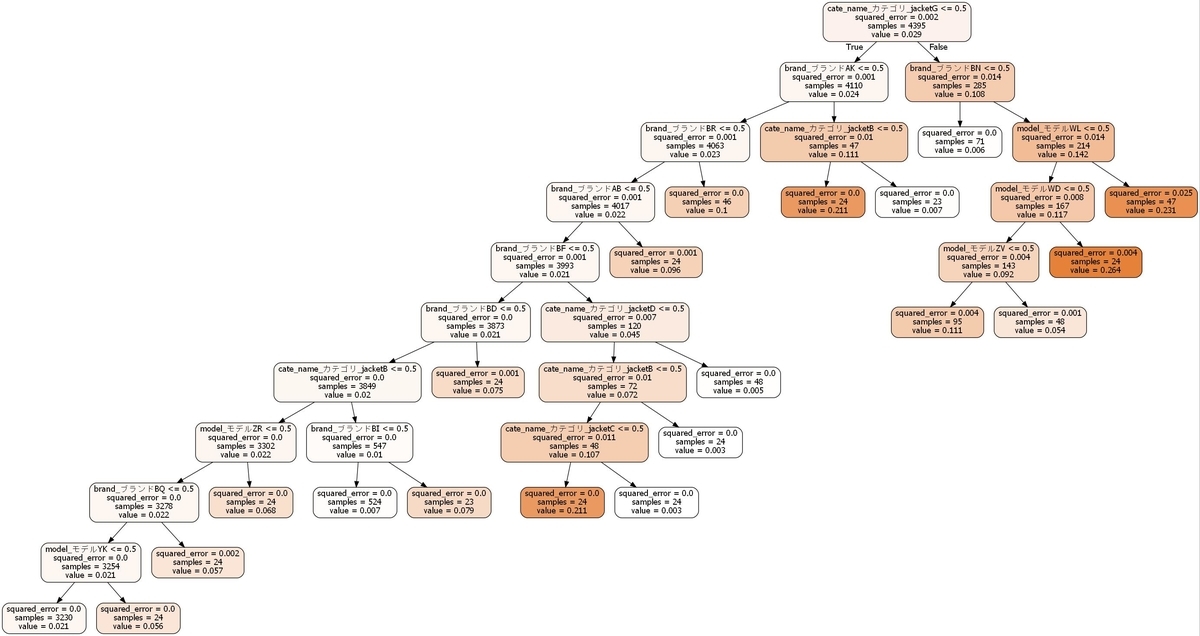
出来上がった決定木を見ながら、解釈をしていきます。
注意点として、決定木は、lossが少なくなるように分割していくアルゴリズムであるため、上位に出てくる変数が、必ずしも、CVRを高くする変数とは限りません。
valueを確認しながら、どのような分割がなされているか、確認していきます。
- まず、カテゴリ_jacketGが最初のノードで分割されるようになっています。
そして、右に分割されたノードのvalueは0.108と左の0.024のノードよりも高いため、カテゴリが、カテゴリ_jacketGの場合、CVRがかなり高くなると解釈できます。 - では、カテゴリ_jacketGであれば、なんでもよいかというと、その次の分割を見てみると、ブランドがブランド_BNである場合、valueが0.142、そうでない場合は、0.006となっているため、カテゴリ_jacketGは、ブランド_BNが一強のカテゴリであることが分かります。さらにノードを下ると、ブランド_BNの中でもモデルによって、CVRは異なるようですが、全般的には、高いCVRを擁していることが見てとれます。
- カテゴリ_jacketGではないノードを見ていくと、いくつかのブランド名でノードが枝分かれするようになっています。カテゴリ_jacketGでなければ、その次は、ブランドの選択が重要である、ということが見てとれます。実際には、企画担当者と会話をしながら、表示されているブランドをグルーピングなどして、整理しました。
- さらに深く確認しようと思えば、ブランド_BFは、カテゴリによって差がある、カテゴリ_jacketBカテゴリかどうかで、ノードが分かれる、と状況に応じて、確認していくことも可能です。
決定木の場合、初めにも話した通り、視覚的に分析結果を表せるため、ドメイン知識が少なくても、結果の解釈が行いやすいことはメリットではないかと思います。また、企画担当者側も分析結果が分かりやすいので、スムーズに相談が行いやすくなると思います。
なお、解釈性が高い決定木分析ですが、注意点もあります。
まず、決定木分析は機械学習のアルゴリズムの中では、精度が高くなりにくい、と言われています。これは、モデルが学習データに過学習しやすく、汎用性が低くなってしまうためです(今回は、生データや、感覚値ともずれていないという判断をして、精度はあまり重視しませんでしたが。)。決定木に限りませんが、あくまでも学習データとして使用したものの説明にしかなっていませんので、将来的にも同じ傾向があるかどうかは、確実ではありません。特に、一時的に強い需要があったデータなどが含まれると、当然、そのデータの影響が強く出てしまうため、注意が必要です。
今後の展望
今回は、比較的、カジュアルな分析でしたので、そこまで、多くない変数で実施しました。感覚としては、企画担当者側も理解しやすかったのではないかと感じましたので、決定木を使ったデータ分析は有用であると考えています。
変数を増やしていくことで、目的とする変数に対して、どういった変数が影響を与えているのか、さらに詳細な分析を行うことも可能と考えられます。
また、決定木アルゴリズムの発展形として、LightGBMやXGBoostなどのアルゴリズムが、データサイエンス分野では、スタンダードになっているようです。他にも、SHAPなど、今回、実施した内容以外で、機械学習モデルの可視化をする方法が研究されており、自分も現在、勉強中です。
最初にお伝えした通り、エニグモには、データアナリストとは別に、データサイエンティストの職種もあります。データサイエンスのプロフェッショナルがいて、通常のデータ分析を企画担当者の方も普通に行っている環境ですので、ビジュアライゼーションやモデルの説明性といった手法を使って、データとビジネスをうまくつなげていくのが、データアナリストの役割ではないかと考えています。
本日の記事は、以上です。読んでいただき、ありがとうございました。
明日の記事の担当はエンジニアの沖田さんです。お楽しみに。
株式会社エニグモ 正社員の求人一覧