エンジニアの木村です。この記事は Enigmo Advent Calendar 2021 の 13日目の記事です。 いろいろやってますが、BUYチームという購入UXに関わる機能開発を担当するチームのマネージャーもやっています。11月末に行われるブラックフライデー、サイバーマンデーといった大型キャンペーンに備えた開発もそのチームで担当したのですが、今日はそれに備えて行った負荷対策の1つの取り組みについてお話しします。
悔しい思いをした去年のブラックフライデー
平素よりBUYMAをご利用いただきまして、誠にありがとうございます。
— BUYMA(バイマ)| 海外ファッション通販サイト (@BUYMA) November 26, 2020
本日0時頃より、サイトに繋がりづらい状況が続いており、現在復旧に向けて全力で対応を行っております。
ご不便をお掛けしてしまい大変申し訳ございませんが、何卒ご理解を賜りますようお願い申し上げます。
これは昨年のブラックフライデー開始直後のBUYMAオフィシャルアカウントのツイートになります。。悲しいですね。下のリンクから当時のBUYMAの状況を表すタイムラインが見れますが、どういう状況だったか推察いただけると思います。
バイマ OR buyma until:2020-11-27_00:50:00_JST -filter:links -filter:replies - Twitter Search
ユーザーのログイン状態管理が重い
原因の1つは、ユーザーのログイン状態の管理をサービスのメインDBで行っているところでした。スケールが難しいRDBです。最近はアクセス集中時にユーザーのログイン済み比率も増え、そのユーザーのアクセスでは毎リクエストそのDBのテーブルへSELECTが走るのでメインDBが高負荷になり、メインDBなのであらゆる機能へ影響するためサイトとしては繋がりにくくなるという状況でした。もちろん、以前から問題視されていた仕組みではありましたが、ログイン状態の管理という重要な機能でもあり、原作者もおらず、別の仕組みへの移行の難易度が高くずっと放置してしまっていました。
したがって、DBのリソースをログイン管理のために温存する必要があるため、動的コンテンツ(HTMLやAPI)配信にもCDNを入れてキャッシュしたり、DB負荷が高い機能はアクセス集中が予測される時間帯には停止するようにスケジュールしたりなどいろんな手を尽くしていま。しかし、それでもブラックフライデーだけは耐えることができませんでした。
セッションの保存をRDBからredisへ
そこで、ログイン状態の保存先をRDBから、より読み取りレイテンシーが小さく、読み取りの集中にも耐久性のあるRedisへと移行するプロジェクトが始まりました。その移行の際に行った工夫が記事の本題となります。この工夫が、たまたま後日読んだこちらの本で紹介されている移行パターンそのものだったのでこちらの本の用語を使って説明していきます。

利用パターン1:抽象化によるブランチ
現代のソフトウェア開発では1つのコードベースでブランチを切って複数人で並行して行うのは普通ですが、あまりブランチを切ってから長い時間が経つと差分が大きく、レビューやマージが大変になります。そこで、実装を改良しようとしている機能の抽象を作り、既存の実装と並行してその抽象の新しい実装を別に作り、さらにあとで切り替えるという方法が抽象化によるブランチと呼ばれる移行パターンです。大きな変更であっても、寿命の長いブランチを作らずに、他で並行して行われる開発と影響しにくいように開発が可能です。今回の事例で1ステップずつ手順を説明していきます。
今回は抽象というよりはファサードとなるクラスを前に立てて新実装へ切り替えているので、モノリス内でのストラングラーパターンと言っても良いかもしれません。
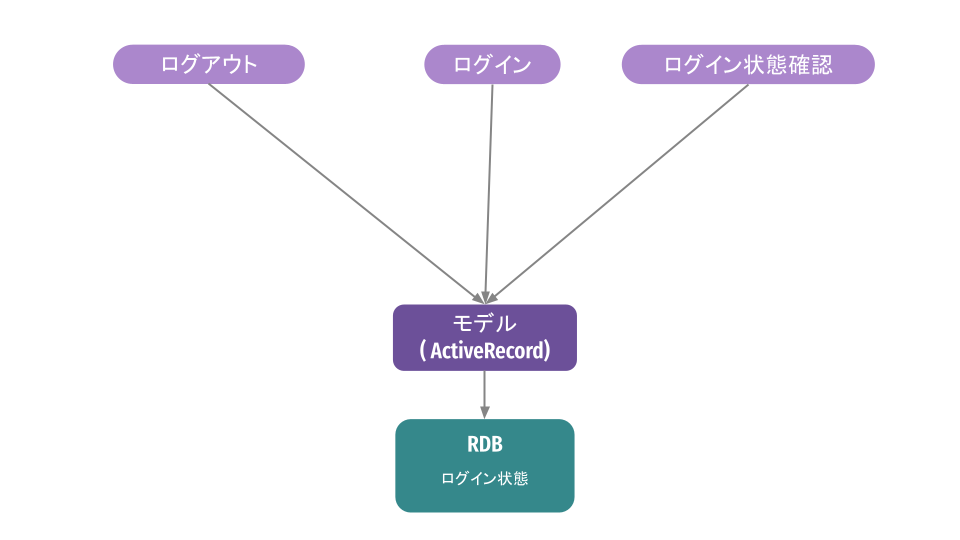
ステップ0:変更前
変更前のアプリケーションはこのような構成でした。ActiveRecordのモデルを介してDBのテーブルを呼び出すというオーソドックスな作りかと思います。
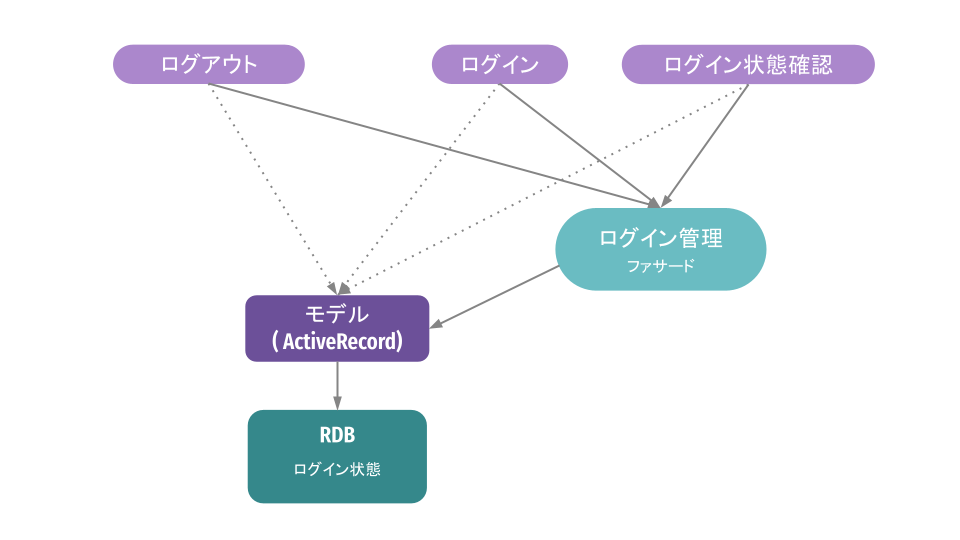
ステップ1:ファサードを作成し、既存のクライアントの向き先を変更
最初に行ったのは、実装の変更を呼び出し元へ影響するのを抑えるため、ログインステータスの操作を抽象化するためにファサードとなるクラスを設けたことです。また、このファサードを利用するように、順次呼び出し元の向け先もこのファサードへ切り替えました。
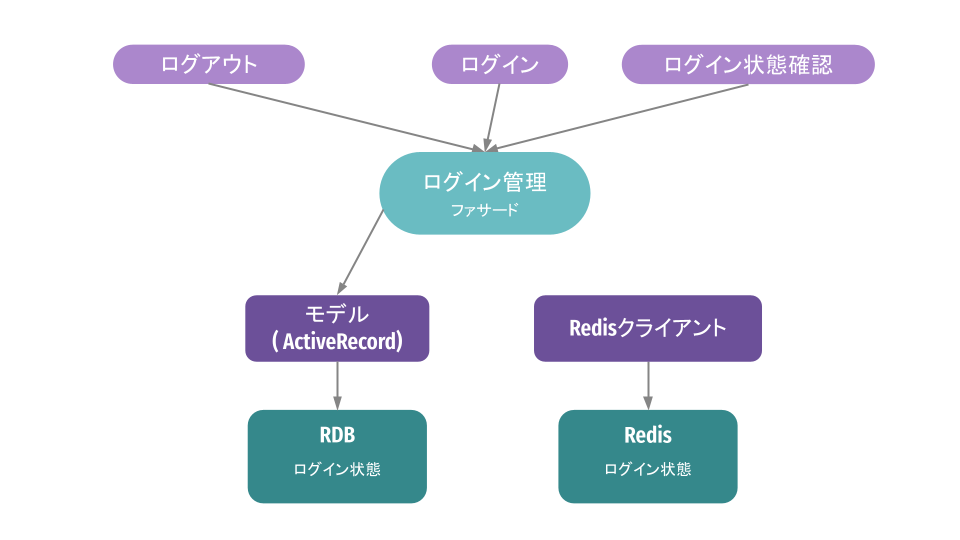
ステップ2:並行して新しい実装を作成
従来の実装を稼働させつつ、新しい実装を横に作成します。実装のソースはデプロイされますが、この段階では事実上、従来の実装だけが動いたままです。
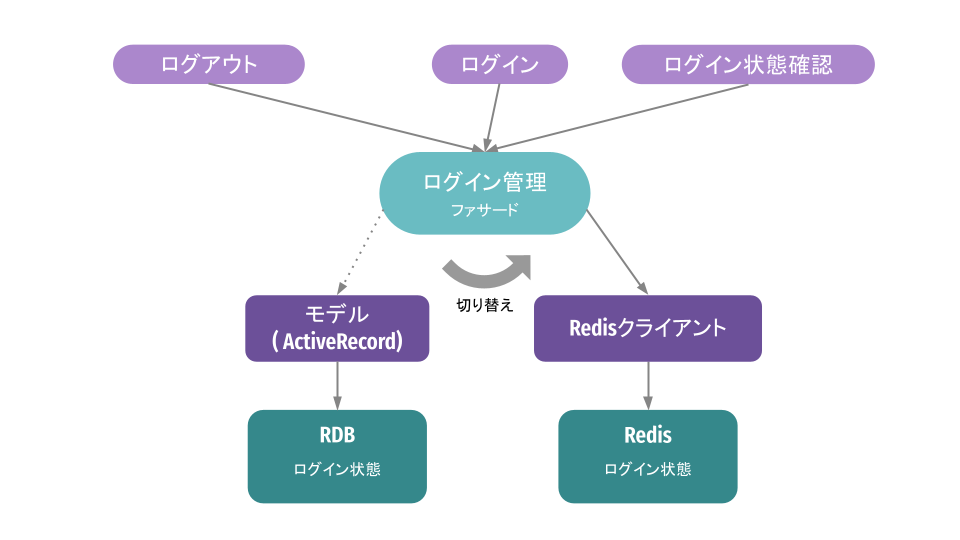
ステップ3:ファサード内で新しい実装を使うように切り替え
ファサード内部を変更して、処理の流れを従来の実装から新しい実装へと切り替えます。この切り替えは後述する 同時実行パターン や カナリアリリース を使って段階的に行いました。
利用パターン2:同時実行
新旧の実装を切り替える時に、それぞれの実装で処理結果が変わらないことを担保する必要があるのですが、通常、デプロイ前にテストを頑張るという手段になると思います。ただ、テスト尽くしても本番環境で起こりうるシナリオは全て網羅することは困難です。特に、今回の変更はユーザーのログイン状態の管理になるので、不具合があると誤ってユーザーをログアウトさせてしまったり、あるいはBANしたユーザーを誤ってログインさせてしまったりなど重大な問題となってしまいます。
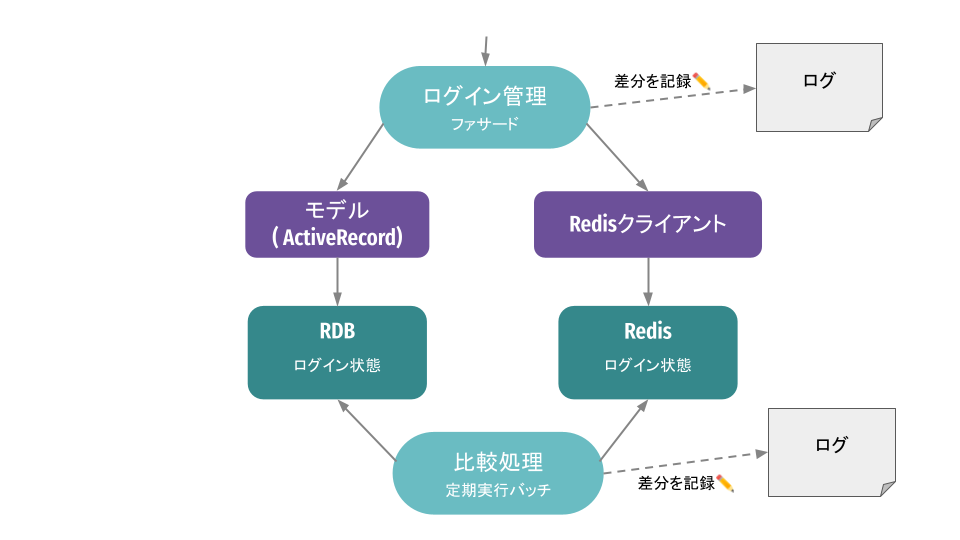
そこで、新実装を本番へ出してしまい、旧実装と同時に新実装も呼び出しつつ、旧実装の結果を呼び出し元へは返しておきながら、それぞれの実行結果を比較して新実装の結果が信頼できるか検証するという 同時実行 というパターンを利用しました。こちらの図のとおり、ファサード側でDB、Redisそれぞれの結果を処理が通るたびに比較検証し、差分があればログに出しておくようにしました。また、ファサードの処理のタイミング以外でもバッチで定期的にそれぞれの内容をスキャンし、差分有無の検証も行いました。差分が出れば原因を調査し、原因を潰していくという作業を差分が出なくなるまで続けました。
カナリアリリースも利用
最初に同時実行モードに入る前に、気になったのはRedisの負荷でした。ほかの機能で導入実績はありましたし、負荷テストはしていたものの、やはり本番のトラフィックを一気に向けるのは勇気が要りました。そこで、徐々に10%ずつ新実装へトラフィックを向けるようにカナリアリリースを行いました。また、同時実行により十分に検証を行い、新しい実装へと切り替えるタイミングでも、予期しないユーザーへの影響の可能性を考え、そのタイミングでも10%ずつ新実装のみの結果を利用するようにしています。カナリアリリースの仕組みは、cookieベースでトラフィックを振り分ける既存のABテストの仕組みを利用しています。
心穏やかに移行完了
以上の工夫によりあまりドキドキすることなく、心穏やかに移行を終えることができました。数ヶ月ほど時間はかかりましたが、抽象化ブランチの仕組みにより、切ってから長時間経った差分の大きいブランチをマージする必要も無かったですし、同時実行によりバグを十分出し切った上で、しかもカナリアリリースで少しずつリリースできたためです。時間がかかるというデメリットはあったものの、特に品質に気を遣う変更には有用かと思います。
負荷対策の効果
ついに迎えたブラックフライデー当日ですが、サイトのパフォーマンスを落とすことなく乗り切ることができました。こちらは、開始直後11/26の0時台の企画メンバーが集うslackのチャンネルの様子です。例年なら不安定になるはずのサイトがサクサク動いていて盛り上がっていました。
もちろん、今回紹介した移行以外にも負荷対策や様々なパフォーマンス改善策を重ねた結果なのですが、それらについてはまた別の機会に紹介しようと思います。