この記事は Enigmo Advent Calendar 2021 の15日目の記事です。
はじめに
寒さが身にしみる今日この頃、みなさん如何お過ごしでしょうか。
最近、○○エンジニアという肩書きがよく分からなくなってきたエンジニアの伊藤です。
アドベントカレンダーの時期になると年末になったんだなという実感が湧きますね。
今回は今年一番注力してやってきたMLOpsについて書いていこうかと思います。
MLOpsとは?については他にも色々と記事があると思うのでここでは触れずに、
導入に向けてどういった手順でどのような取り組みを行ってきたかを中心にご紹介できればと思います。
なぜMLOpsなのか?
弊社でも機械学習を活用したプロジェクトがここ最近増え始めています。
そういった中で課題も色々と見えてきました。
- 属人化
- 実装内容を把握しているのが個人に依存している
- レビューがされていない
- 使用されているバージョンやライブラリがプロジェクトによってバラバラ
- 開発効率の低下
- 同じような処理が色々なところにある
- テストコードがない
- 心温まる運用
- モデルの作成、デプロイは手動
- オブザーバビリティの欠如
こういった状況を踏まえつつ、 今後も増えてくるであろう機械学習プロジェクトを見据えて、MLOpsを導入することになりました。
全体的な流れ
MLOps導入まではざっと下記のような流れで進めました。
- 調査
- MLOpsの定義、方針/目標の設定
- アーキテクチャの設計
- ML基盤の構築
- 開発体制やルール等の策定
- 実装
- CI/CD/CTの検討、設計、実装
- 監視周りの検討、設定
4以降についてはきっちり分けて進めていた訳ではなく、走りながら(実装、構築しながら)並行で進めていくことが多かったです。 以降で各項目からいくつかピックアップして詳細については記載します。
調査
私自身、MLOpsについては何となく分かっていたつもりでしたが、先人たち(先行他社)の取り組みや関連資料を読み漁りました。 ここで特に気を付けていたのは下記の点です。
- 機械学習プロジェクトにまつわる課題としてはどういったものがあるのか?
- 現時点で弊社としての課題感はないが、今後課題になりうるものがないか?
- 先人たちの取り組みを真似るのではなく参考にする
- 各課題に対してどういった考えで、どのようなアプローチをとっているのか
- 個人的な考えですが、組織の規模感や文化といったものが違うのに同じような取り組みをしても失敗すると思っています
MLOpsの定義、目標の設定
MLOpsはバズワードだなんて意見もあります。 MLOpsという単語自体が一人歩きしている感もあるかなと思います。 なので一通り調査が終わったあとは弊社におけるMLOpsを定義することにしました。
今更ながら弊社のメンバー構成を紹介すると下記の通りで、スモールスタートにはちょうど良い人数かなという印象です。
- データサイエンティスト(以降、DS) ✕ 2名
- エンジニア(以降、Ops) ✕ 2名
エニグモにおけるMLOps
「DS(ML)とエンジニア(Ops)がお互いの役割を理解し、強調し合うことで、 機械学習モデルの実装から運用までのライフサイクルを円滑に進めるための仕組みづくりやその考え方」

方針
続いて方針についてです。3つ挙げました。
小さく始めて、大きく育てる
同じ言葉で話せるようにする
マネージドサービスの活用
小さく始めて、大きく育てる
- 最初からあれも、これもと色々なことを詰め込みすぎない
- いつまで立っても設計が固まらず、システムの構築や運用が始まらないというのは一番避けたい
- MLOpsを取り巻く環境はまだまだ成熟しておらず、ノウハウや技術も発展途上の段階
- 柔軟性が高くスケールする基盤であることを第一としてシステムを設計、構築する
同じ言葉で話せるようにする
- スキルセットやメンタルモデルが異なるメンバー同士で作業を進めていく上ではどうしてもコニュニケーションコストは高くなる
- エンジニア同士では暗黙知としているようなルールやお作法についてもきちんと明文化し、使用するツールやフレームワークなども共通化
- ガチガチのルールで縛るのは好きではないので、バランスには注意
マネージドサービスの活用
- 限られた人的リソースの中で対応していくにはどうしても人がボトルネックになりがち&人的コストはスケールさせるのが難しい
- お金で解決できるようなところは積極的に利用する
- 何でもかんでもマネージドという訳ではなくバランスが大事
- コスト(人とお金) X システムとしての柔軟性は意識する
目標

最後に具体的に何をしていくか、どこを目指すかの目標についてです。 ひとまず今期(2021年)としては下記を目標として挙げました。
DSが開発しやすい環境作り
- UIベースでの実験管理
- 再現性の確保(今期はデータではなく環境面にフォーカス)
- パイプラインのバージョン管理、ライブラリ、フレームワークの統一
- 各種ルール化(明文化)
- コーディング規約、レビュー規則、ログ仕様、開発フロー
- 実験段階から本番環境へのデプロイがシームレスに可能
- ドキュメントの充実化
開発コスト削減
データの可視化と監視
- モデルの性能指標など、可視化して確認したいデータが見たい時に見られる状態
- 過不足のない監視、アラート
変化に強い基盤構築
- 汎用性が高く、スケール可能な基盤であること
チームとして1つの目標を目指す上で、言葉の定義や、目標の明文化というのはとても大事だと思っているので、 この辺については特に丁寧に行いました。
また目標としてやるべきことを明確化することと合わせて、やらないこともあえて決めておきました。
どうしても作業を進めていく中で「こんなこともできるとうれしいよね」みたいなことは出てきます。
方針にも挙げていますが、まずは小さく始めることを第一としていたので、こういった迷うケースでも
チームとしてブレずに進めたのは良かったなと思います。
アーキテクチャの設計
続いてアーキテクチャの設計についてです。
ツール選定
アーキテクチャを設計する上ではまずはMLワークフローの中心となるツール選定を行いました。
MLOpsを取り巻くツールはMLOps Toysに集約されるようにとても多岐に渡ります。
この1つ1つを調査、検証していてはとても時間がかかるのでツール選定については時間をかけずに、
下記の観点で一番相性の良さそうなKubeflowを選択しました。
- 利用事例が多い
- 開発が活発
- 柔軟性がある
- まずはPipelinesのみ導入し、その後必要に応じて他のコンポーネント導入が可能
- Kubernetesの構築、運用実績がある
アーキテクチャ
分析等に扱うデータはBigQueryに集約している関係で、そのデータを扱うML系のプロジェクトもGCP上で構築することが多いです。 そのため今回新たに構築するML基盤についてもGCP上で構築しています。 またKubeflow PipelinesについてはそのマネージドサービスであるAI Platform Pipelinesを利用することとしました。
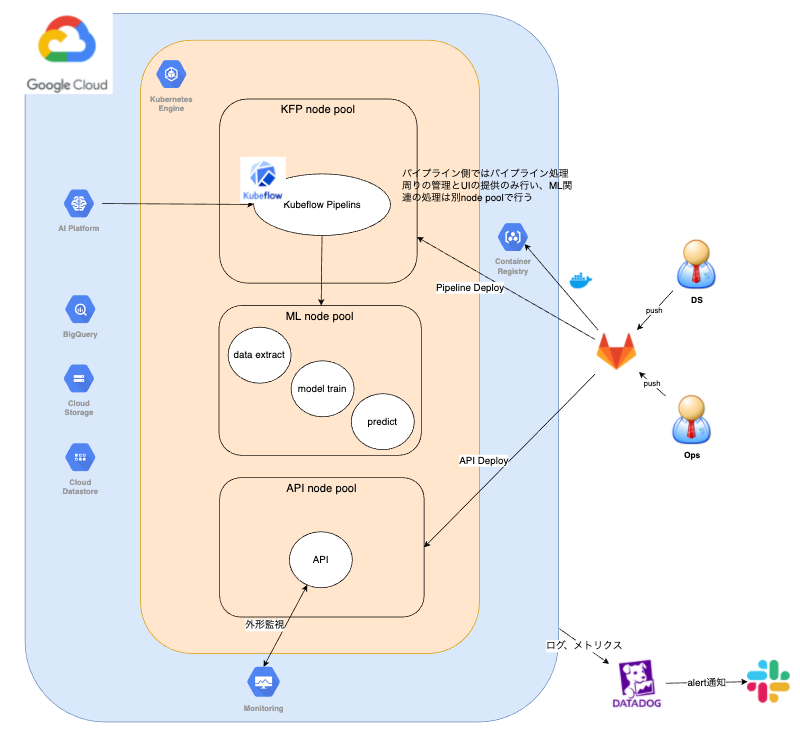
- ML基盤としてGKEを利用
- GCPマネージドサービスとして下記を利用
- AI Platform Pipelines
- BigQuery
- Cloud Storage
- Cloud Datastore
- Container Registry
- 各種メトリクスの可視化、監視にはDatadogを利用
ML基盤の構築
ML基盤としては上記の通り、GKEをインフラとしつつ、AI Platform Pipelinesを利用しています。
基本的には全てIaCとしてterraformで管理、運用していますが、AI Platform Pipelinesは未対応だったため対象外として扱っています。
また、システムに名前があった方が良いよねということで、
メンバーそれぞれで候補となる名前をいくつか挙げて、投票で一番多かったCapellaという名前に決まりました。
CI/CD/CTの検討、設計、実装
CI、CD、CTともに全てGitlab CIを利用するようにしました。
Cloud Buildなども検討しましたが、Gitlab CIの方がより柔軟性が高かったのと、元々別のシステムでもGitlab CIを利用していたというのが理由です。
CI/CD
- テスト環境
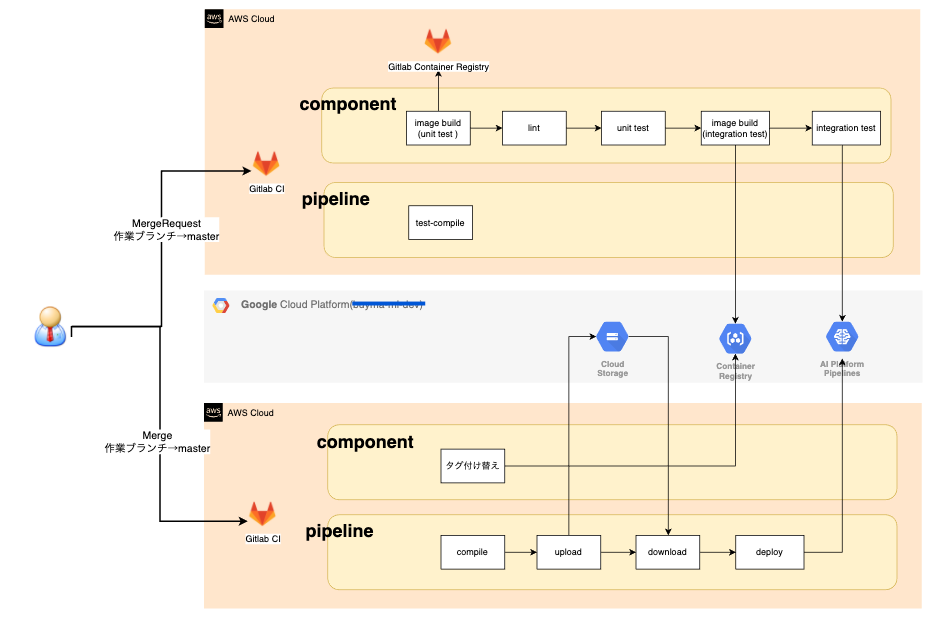
- 本番環境

- ポイント
各工程の細かい処理については置いておいて、ポイントについてここでは記載します。
CT
パイプラインの実行トリガーをどこに持たせるかは正直一番悩んだところです。 Kubeflow Pipelines側に標準実装されているスケジュール機能を利用するのが良いのかなとも思いましたが、下記の理由からGitlabパイプラインスケジュールを利用して定期実行するようにしています。
- CI/CD用に作成したツールを使い回せる
- gitブランチと紐付けてスケジュール実行が可能
- master → テスト環境
- production → 本番環境
- CI/CDジョブとシームレスに扱うことができる
- CI/CD/CTがすべてGitlabで管理されているという分かりやすさ
- Kubeflow Pipelines側のスケジュール機能で実行した場合に、MLパイプラインの実行ステータスの通知をどうするかの検討が別途必要だった
- Gitlab側であればパイプラインステータスを判断してSlack連携が可能なことは確認済みだった
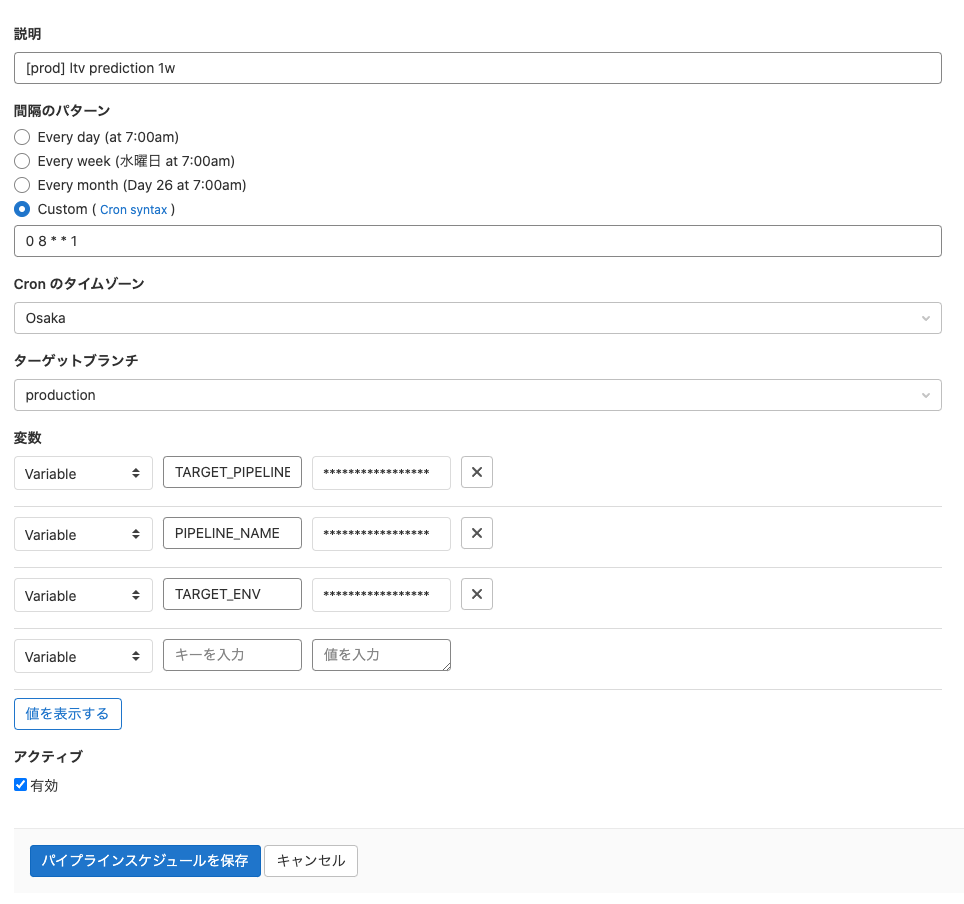
なお、下記がGitlabパイプラインスケジュールのUIになります。 内容としても直感的に分かりやすく、cronジョブベースでの定期実行と、設定した変数で処理が分岐できるようにしています。
おわりに
ここまで調査/検討から始まり導入までについて、ざっとご紹介させていただきました。 書ききれていない内容もありますが、少しでもどういった取り組みをしているのかが伝われば幸いです。
また今回構築したシステムについてはまだまだ未熟で、これからどう成長させていくかが大事かなと思っております。 そんな訳でエニグモではMLプロジェクトを一緒に盛り上げていくメンバーについても募集中です! この記事を見て少しでも興味を持っていただけたら、まずは雑談からでもOKですので気軽にご相談ください。
明日の記事はエンジニアの平井くんです!きっとワクワクするような内容だと思うのでめちゃくちゃ楽しみですね!!!
株式会社エニグモ すべての求人一覧