こんにちは、AIテクノロジーグループの太田です。
普段は商品のカタログデータ基盤を開発・運用するチームで業務に携わっております。エニグモではそういったデータやAI関連の技術基盤としてGCPを利用しており、そこで利用したWorkflowsについて紹介したいと思います。
この記事はEnigmo Advent Calendar 2025の17日目の記事です。
- 1. はじめに:なぜこの構成に至ったか
- 2. Goolge Cloud 構成:全体アーキテクチャ概要
- 3. 技術選定:なぜ Cloud Composer ではなく Workflows なのか
- 4. 実装サンプル:Workflows から Dataflow を起動する
- 5. Workflows を採用する上で許容した「不便な点」
- 6. まとめ
1. はじめに:なぜこの構成に至ったか
- 背景
毎日追加・更新される商品データを Vector Search のインデックスに反映させる必要があった。
Cloud Composer (Airflow) の利用実績はあったものの、より安価な Workflows に興味があった。 - 課題
「差分抽出 → 画像処理(Embedding) → インデックス更新」という一連のフローを毎日決まった時間に実行したい。
各処理ステップ(特に画像処理とインデックス更新)は時間がかかるため、タイムアウトやリトライ制御を考慮する必要がある。
当然コストは抑えたい。 - 結論
Cloud Composer を使わず、Workflows + Cloud Scheduler を採用することで、管理コストと金銭的コストを最小限に抑えたアーキテクチャを構築した。
ポイントは、重たい処理(画像処理・インデックス更新)は Dataflow に任せ、Workflows はあくまで「順序制御」に徹する構成にしたことです。
2. Goolge Cloud 構成:全体アーキテクチャ概要
処理の流れは次のとおりです。
- Cloud Scheduler 毎日定時に Workflows をトリガー。
- Workflows: 全体の指揮者。以下のステップを順次実行。
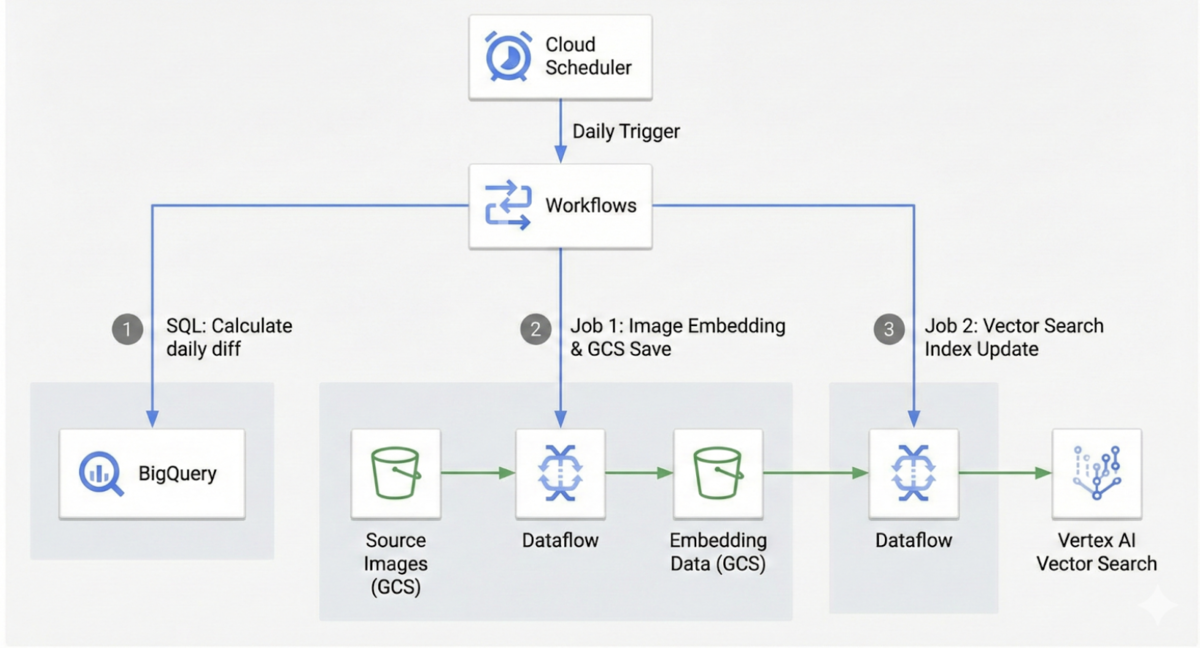
ポイントは、長時間実行かつ単発で実行する機会がある Dataflow の実行を別の Workflows に委ね、メインの Workflows から別の Workflows を呼び出すようにしたことです。
Dataflowの実装については、本記事の趣旨から外れるので省略いたします。
3. 技術選定:なぜ Cloud Composer ではなく Workflows なのか
このセクションで、他の選択肢と比較し、なぜ今回の構成に至ったかを解説します。
| 比較項目 | Workflows | Cloud Composer |
|---|---|---|
| 特性 | サーバーレスで軽量、直線的なフローに最適 | 複雑な依存関係に強いが、常時稼働が必要 |
| コスト | 安価(実行回数課金) 1000ステップ0.01ドル1 Google Cloud 外へのアクセスを要する場合は1000ステップ0.025ドル |
高い(小規模でも月額数万円〜)2 実際に月額約8万円かかっています |
| 採用/不採用の決め手 | 今回の処理が「直線的」であり、複雑なDAGが不要だったため | 日次バッチ一つに対してはオーバースペック |
運用実績があったからといって、「とりあえず Airflow」とせずに、ワークフローの複雑さに応じてツールを選定できた点が良かったです。
実際に使ってみて、単純な A -> B -> C というフローなら Workflows の方が圧倒的に運用・コストメリットが大きいことが実感できました。
4. 実装サンプル:Workflows から Dataflow を起動する
ここでは、実際に Workflows を使って Dataflow (Flex Template) を起動するための定義(YAML)を紹介します。
【コード解説のポイント】
Dataflow の Flex Template を利用することで、Docker イメージ化したジョブをパラメータ付きで呼び出せます。
Workflows 側でジョブの完了を待機する(ポーリングする)ようにしました。
googleapi 3 で Dataflow 以外の各種 Google Cloud のプロダクトへアクセスすることができるので、参照してみてください。
【サンプルコード(YAML)】
実際に作成した Dataflow を起動する Workflows の定義ファイル(main.yaml)の一部を掲載します。
- main.yaml の抜粋イメージ
steps: - init: assign: - project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")} - location: "asia-northeast1" - job_name: "dataflow-launcher" # デプロイするときに --set-env-vars で設定した環境変数をここで読み込む - sdk_container_image: ${sys.get_env("sdk_container_image")} - gcs_bucket: ${sys.get_env("gcs_bucket")} # YYYYMMDD 形式の日付 - ymd: ${text.replace_all(text.split(time.format(sys.now()), "T")[0], "-", "")} # 画像処理をするので時間がかかる Dataflow を実行するステップ - dataflow_start_crop_embedding: call: googleapis.dataflow.v1b3.projects.locations.flexTemplates.launch args: projectId: ${project_id} location: ${location} body: launchParameter: jobName: ${job_name + ymd} containerSpecGcsPath: ${gcs_bucket + "/templates/your-template-spec.json"} parameters: sdk_container_image: ${sdk_container_image} environment: stagingLocation: ${gcs_bucket + "/templates/staging"} tempLocation: ${gcs_bucket + "/templates/temp"} serviceAccountEmail: ${Dataflow 実行権限を持つ Service Account} result: dataflow_result next: initialize_polling # 以下、Dataflow を完了まで監視するステップ # ループした回数だけステップ数が増えてコストも増えていくのでループ数には注意してください。 - initialize_polling: assign: - counter: 0 # "max_retries * 60秒 (wait_60_secondsで定義) = 1時間"なので、最大1時間ポーリングを行う。 - max_retries: 60 next: poll_job_status - poll_job_status: call: googleapis.dataflow.v1b3.projects.locations.jobs.get args: projectId: ${project_id} location: ${location} # run_dataflow_job ステップの return から参照できる。 jobId: ${dataflow_result.job.id} result: job_status next: check_job_status - check_job_status: switch: - condition: ${job_status.currentState == "JOB_STATE_DONE"} next: job_succeeded - condition: ${job_status.currentState == "JOB_STATE_FAILED" or job_status.currentState == "JOB_STATE_CANCELLED"} raise: ${"Dataflowジョブ " + dataflow_result.job.id + " が失敗しました。ステータス " + job_status.currentState} - condition: ${counter >= max_retries} raise: ${"Dataflowジョブ " + dataflow_result.job.id + " が1時間以内に完了しませんでした。タイムアウト。"} - condition: ${true} next: increment_counter - increment_counter: assign: - counter: ${counter + 1} next: wait_60_seconds - wait_60_seconds: call: sys.sleep args: seconds: 60 next: poll_job_status - job_succeeded: return: "SUCCESS"
【サンプルコードをデプロイ】
作成した Workflows の定義ファイルをデプロイ4します。
gcloud workflows deploy sample_workflow \
--source=main.yaml \
--location="asia-northeast1" \
--project=${PROJECT_ID} \
--service-account=${SERVICE_ACCOUNT_EMAIL} \
--set-env-vars sdk_container_image=${Artifact Registry にpushしたdockerイメージ} \
--set-env-vars gcs_bucket="gs://YOUR_BUCKET" \
【サンプルコードを実行した結果】
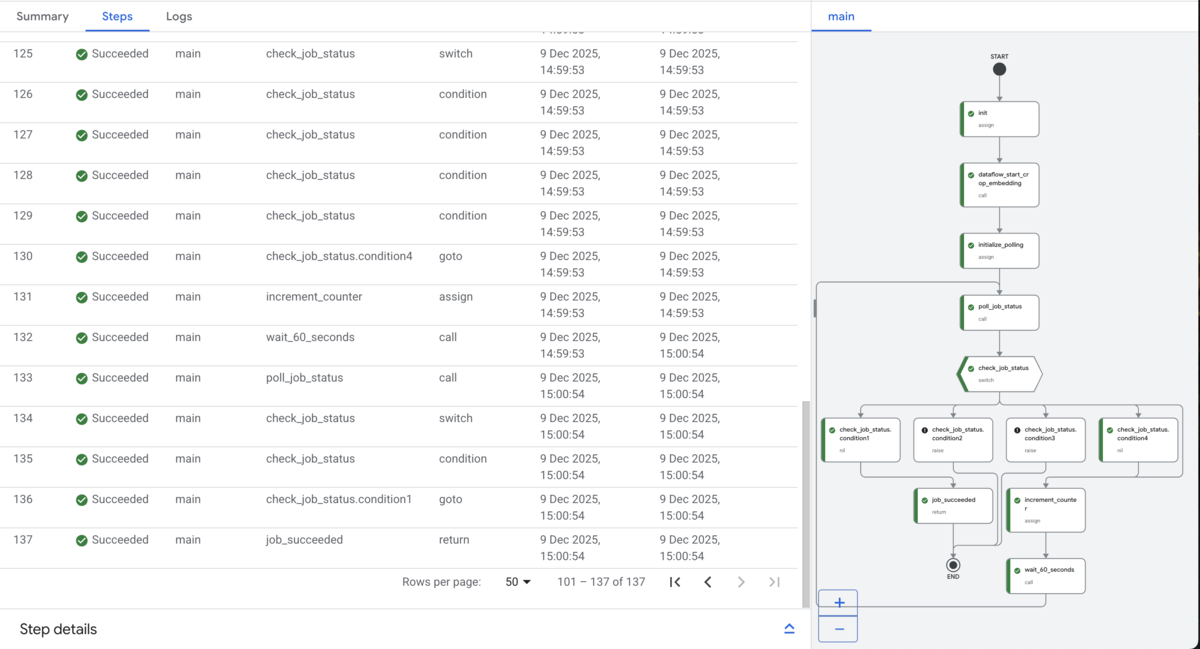
ループしているので実際に実行されたステップ数は137でした。
コストは 137 * 0.01 / 1000 = 0.00137 ドルになります。
5. Workflows を採用する上で許容した「不便な点」
コストと手軽さは魅力的ですが、導入に際しては以下のデメリットも考慮する必要がありました。
開発体験のクセ(YAML地獄)
ローカルテスト・デバッグの難易度
ステップ間のデータ受け渡し制限(メモリサイズ)
- 課題
Workflows は大規模なデータをステップ間で直接受け渡すこと(ペイロードサイズ制限)には向いていません。 - 対応
今回の設計では、画像データそのものや大量のリストは Workflows 上を通過させず、必ず GCS のパスや BigQuery のテーブル名といった「参照情報」のみを受け渡すように徹底しました。
- 課題
ベンダーロックイン
6. まとめ
Workflows + Cloud Scheduler の組み合わせにより、日次の Vector Search インデックス更新を完全自動化できました。
コスト面以外では、インフラ管理コスト(Cloud Composer の環境維持など)を削減し、本質的なロジック開発に集中できることが Workflows の大きなメリットに感じました。
デメリットでYAML記法に言及しましたが、逆に言えば、どなたでも気軽に試してみることができるとも言えます。コストも軽いのでこれを機に是非一度お試しください。
読者の皆様がこれで良い体験を得ることができましたら私としても大変嬉しく思います。
明日18日目はAIテクノロジーグループの吉田さんです。