こんにちは。
インフラグループKubernetesチームの福田です。
みなさん、システムの監視はどうしているでしょうか?
弊社では幾らかのサービスをEKS上で動かしており、その監視にはDatadogとPrometheus Stackを使っています。
この記事では特にPrometheus Stackを使ったEKS周りの監視構成について、その概要を紹介したいと思います。
クラスタ毎の構成
まず、我々は以下のKubernetesクラスタを運用しております。
構成は下図のようになっています。
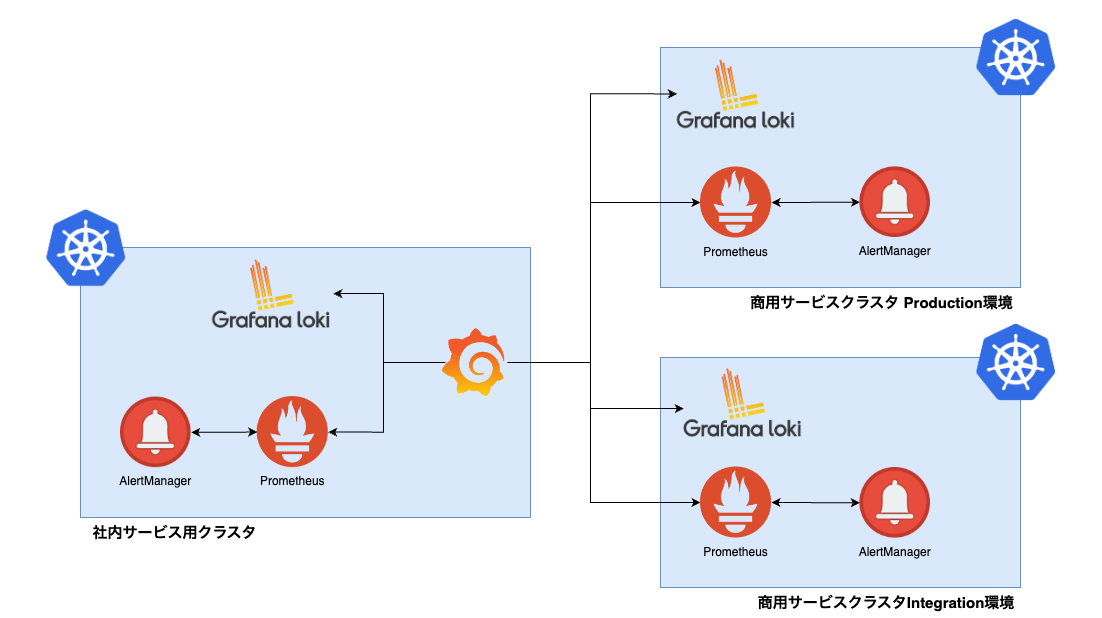
Grafanaだけ中央集権的に社内サービスクラスタにのみ配置し、それ以外のPrometheus等の監視コンポーネントはクラスタ毎に配置しています。
また、各クラスタにはPrometheus Operatorをインストールしており、Prometheus自体の構築やPrometheusのコンフィグの管理はPrometheus Operatorを介して行っています。
監視項目
ここからは監視項目とその方法について紹介したいと思います。
外形監視
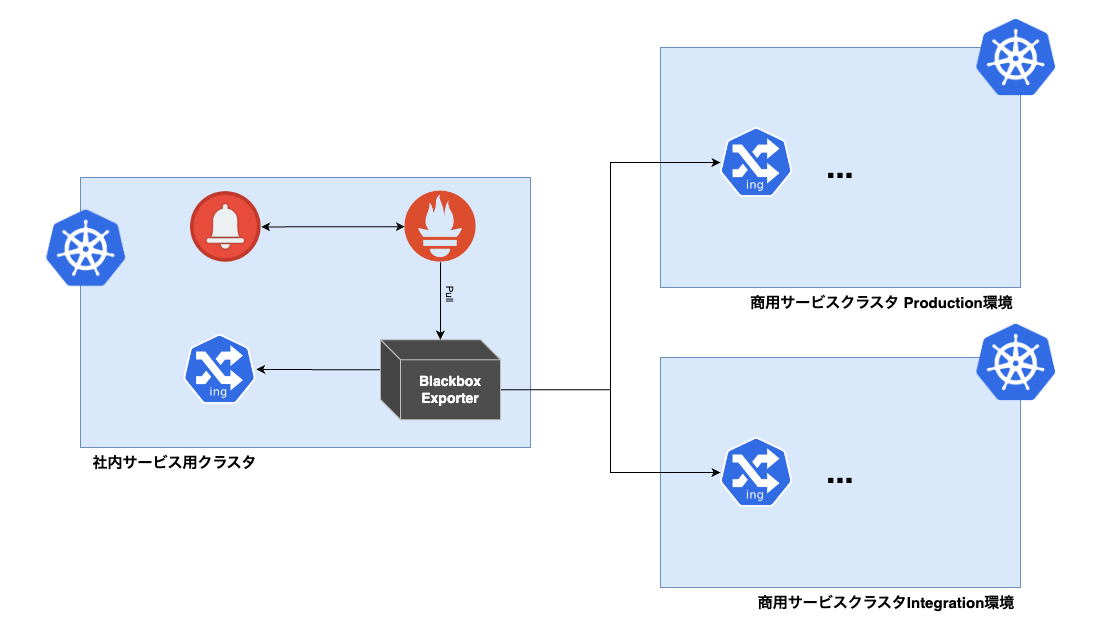
社内サービス用クラスタ上にあるBlackbox Exporterから必要なエンドポイントへ外形監視をしています。
各クラスタのAWSアカウントはそれぞれ分かれているため、商用サービスクラスタへの通信はAWSアカウントを跨ぐようになっています。
worker nodeの監視
node単位でのリソース使用量等の情報はDaemonSetとしてインストールしているNode Exporterからメトリクスを収集しています。
コンテナの監視
コンテナ単位でのリソース使用量等の情報はcAdvisorからメトリクスを収集しています。
cAdvisorは自前でデプロイしたものではなく、kubeletに組み込まれているものをそのまま利用しています。
各種アプリケーションの監視
自社で開発したアプリケーションについては原則はPrometheusではなく、Datadogで監視を行っています。
ただし、Argo CD等のOSSについてはそれらのアプリケーションが公開しているmetrics用エンドポイントからPrometheusメトリクスを収集しています。

Logの集約
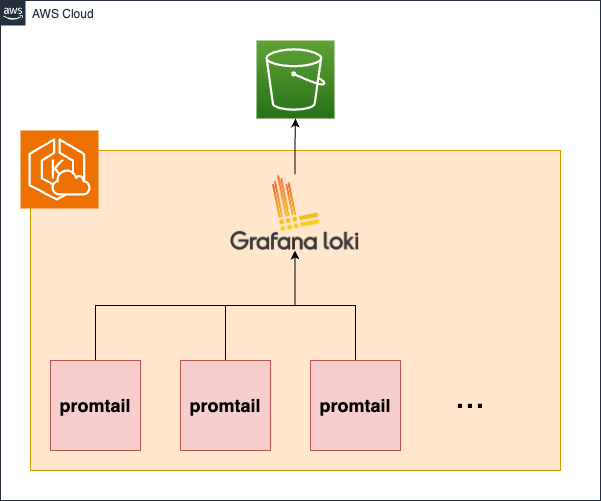
Logの集約はGrafana Lokiで行っています。
DaemonSetとして各nodeにインストールしているPromtailが各クラスタにあるLokiへログを送信する構成です。
また、ログデータは永続化するためにLokiの機能を使ってS3に保存するようにしています。
まとめ
本記事では、Prometheus Stackを使ったEKS周りの監視構成について概要を紹介させていただきました。
ここでは構成の概要を紹介しただけですが、ハマりポイントや改善ポイントについても知見がある程度溜まった段階で、今後紹介できればと思います。
また、エニグモではエンジニアを含む各種ポジションで求人を募集しております。
株式会社エニグモ すべての求人一覧