こんにちは、データアナリストの井原です。
この記事は Enigmo Advent Calendar 2023 の 5日目の記事です。
この記事では、不正対策のデータ分析から機械学習モデルの導入を決定した経緯についてご紹介します。
私は普段、データアナリストとしてBUYMAの様々な業務にデータ分析担当としてかかわっています。
分析内容は施策の効果検証、ユーザーの行動分析、売れ筋商品の分析などマーケティング的な要素が多く、ビジネス判断の正確性を上げることを目的とした業務が多いです。
機械学習については、ある程度の知識と経験もありますが、本職のデータサイエンティストが社内にいることもあり、どちらかといえば、統計検定や因果推論などの手法を使用することが多いです。
ただ、今回は、不正対策をしているチームからの不正検知の精度を上げたいという相談があり、検証の結果として機械学習モデルを導入しようという結論になりました。
本記事では、その経緯について詳しくお伝えしたいと思います。
なお、この記事では、立ち上がり~検証内容の決定~検証実行と、検証を進めていったプロセスにフォーカスして記載します。
分析内容の詳細(プログラム、アルゴリズムの説明など)は記載しませんので、ご了承ください。
依頼の経緯
近年、多くのECサイトで決済の不正利用の被害が増えています。
決済の不正利用とは、フィッシングなどの悪質な手段によって他者のクレジットカード情報やサービスのログイン情報を不正に取得し、それを利用して換金性の高い商品を購入しようとする犯罪行為です。
BUYMAでは、高額なブランド品が新品で購入できるということもあり、一定量、こういった不正利用による被害が発生してしまう状況にあります。
対策として、不正利用を防止するためのチームが社内に存在しており、日々対応を行なっています。
今回、そのチームから以下の依頼をデータ活用推進室にいただきました。
- これまで、チームの知見を元に、不正疑いのある取引を検知する条件をルールベースで設定し、条件に該当した取引を一時的に止めて確認する(以下、買付保留*1)という対応を行っていた。
- 近年、不正利用のパターンが多様化してきており、不正の事前検知の難易度が上がってきている。
- 蓄積したナレッジとデータを活用し、データから不正な取引を止めることが出来ないか?
ということで、こちらの依頼に自分がアサインされ、データから不正検知を行うことが出来るか?を検証してみることになりました。
分析の進め方の策定
最初に実施したこととしては、検証内容を整理することです。
データ分析に関わっている方は想像つくと思いますが、分析のステップの中でおそらく一番重要なステップになります。
ここで、何を知りたいのか?それを知るための適切な方法は何なのか?を徹底的に考え、ビジネス側(今回は不正対策のチーム)と合意する必要があります。
目的は不正の早期検知ができることと明確でしたので、ここでは、検証方法について以下の3点を整理し、ビジネス側に提示しました。
- 精度の測り方
- 分析手法
- 検証に使用するデータ
ひとつづつ、見ていきます。
1.精度の測り方
今回の案件では、精度をどのように定義するのか?が要所の一つでもありました。
単純に考えると、不正な取引を何件検知できたか?が指標になるように思われます。
この考え方であれば解決は簡単です。全ての取引を買付保留にしてしまえばよいのです。
全ての取引を買付保留にして、全て不正かどうかをチェックすれば、理論上、不正はすべて止められます。
しかし、当然ながらこの方法は取れません。
全ての取引を不正疑いとしてチェックすることはコスト的に現実的ではないですし、ユーザーからしても取引完了までの時間が長くなるため、ユーザビリティーが下がってしまいます。
今回のような検証内容の場合、見るべき指標は二つあります。
- 不正と予測した取引が実際に不正である確率(以下、買付保留的中率)
- 不正である取引を不正と検知できる確率(以下、検知成功率)
ちなみに、機械学習の二値分類タスクでこの指標はよく出てきます。
(それぞれの指標は機械学習の言葉では適合率、再現率と言います。詳細は書きませんが二値分類の指標は他にも色々あったりしますので、知っておくだけでも便利です。)
図にしてみると以下のようになります。

基本的に、この指標は片側を改善すると片側が悪化する傾向があります。
例えば、検知成功率を上げるためには、買付保留の数を増やす必要がありますが、(きれいに不正だけを検知することは基本ないので)母数が増えて買付保留的中率は下がります。
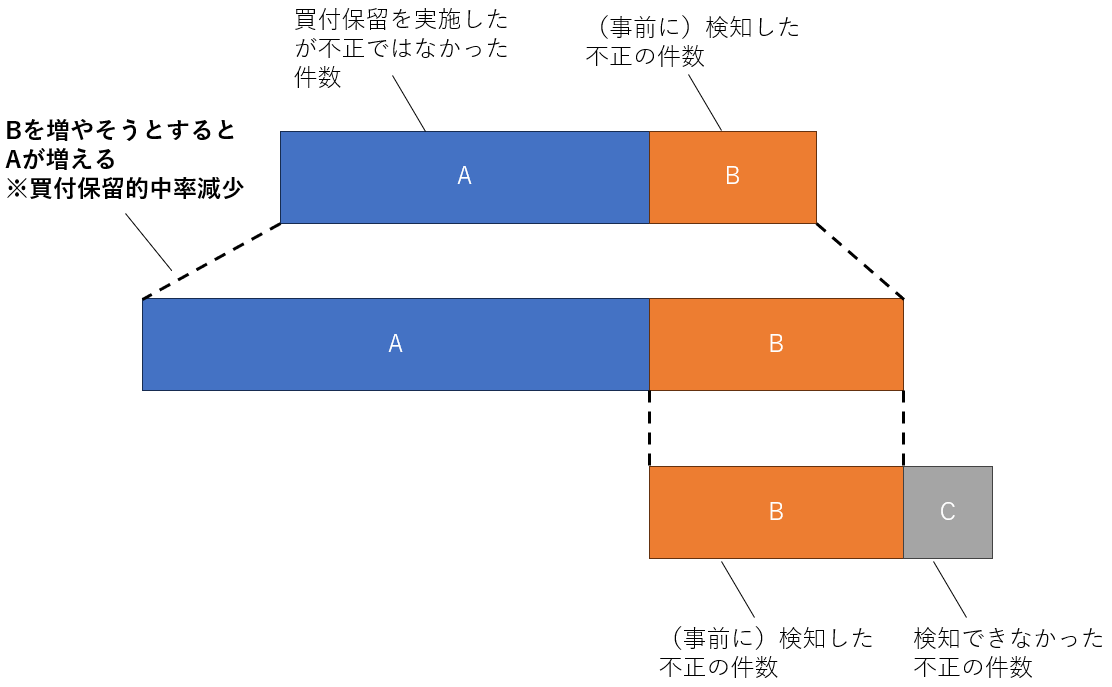
逆も同様で買付保留的中率は、基本的に母数を減らすことになるので検知成功率が下がります。
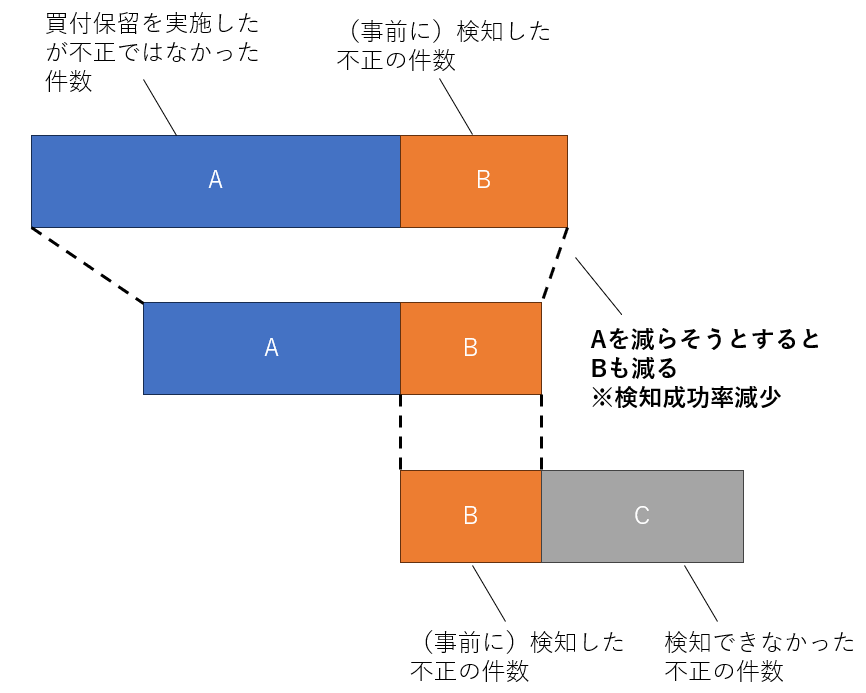
このあたりをどのラインで許容できるかは、ケースバイケースになります。
本ケースでも、二つの指標を総合的に見ながら、ビジネス側と方針を詰めていくこととしました。
2.分析手法
指標を決めましたので、どのように精度を改善していくか?という手法の選択に移ります。
選択肢としては、以下の二つの手法を考えました。
- 決定木分析で重要な要素を抽出し、ルールベース案を検討する。
- LightGBMで機械学習モデルを構築し、不正予測スコアから推定する。
検証内容的に機械学習モデルを使った方が、精度は改善するだろうという感覚がこの時点でありました。
しかし、それでもルールベース案の検討を入れたのは、コスト的な観点からです。
経緯にも記載した通り、これまでも不正対策のチームではルールベースで買付保留を行うという運用を行ってきていました。
つまり、ルールベースであれば、すでにあるその運用に乗せることができ、開発などのコストも少なく短い期間での対応が可能でした。
一方の機械学習は全社での活用歴はいくつもあるものの、不正対策への適用は初めてでしたので、検証はともかく実行環境の構築にはコストも時間もかかります。
そのため、ルールベースでそれなりの精度改善が見込めるのであれば、わざわざ機械学習環境を構築する必要がなくなるというコスト的メリットがあるのです。
3.検証に使用するデータ
最後に検証に使用するデータの決定です。
幸いなことに、これまでの不正対策の取り組みのおかげでログは蓄積されていましたので、どの取引が不正だったのかという実データを使うことが出来ました。
過去ログは「学習用データ」と「検証用データ」に分割しました。
これは、学習させたデータでそのまま精度を検証すると精度が過剰に高く出て検証にならないので、学習させていないデータで検証を行う必要があるためです。
また、最新の1ヶ月のデータは、完全に学習用データから除外しました。
不正というのは一人の不正者が不正を一つだけ行うというものではないため、過去のデータ同士だとランダムに分割しても類似パターンを学習してしまう可能性があります。
そのため、未知のデータに対応しても精度がよいか検証する必要があり、最新1ヶ月分はそれ用の検証用データとしました。
まとめると以下のようなイメージになります。

分析の実行
検証方法をビジネス側と合意しましたので、ここからは分析を実行していきます。
前項で書いた通り、「決定木分析からルールベース案の検討」と「LightGBMを使った機械学習モデルの構築」を行っていきます。
1.決定木分析からルールベース案の検討
途中の作業は省略しますが、決定木分析を行うと以下のようなアウトプットが出てきて、どのような変数・閾値で分割すると、不正とそうではない取引をうまく見分けることが出来るかを可視化してくれます。
※変数名や結果はダミーです。

決定木の結果をそのまま使ったわけではないですが、重要そうな要素と閾値を見ながらルールベース案を4つほど作成しました。
また、決定木自体も予測を行うことが出来ますので、決定木によるモデル推定というパターンも用意しました。
これら5つのパターンと既存のパターン、合計6パターンについて、全組み合わせ(63パターン)での予測結果と精度を算出しました。
具体的な数字は出せませんが、この時点でモデル推定の精度が突出していました。
単純なモデル推定と既存パターンの比較では、買付保留的中率が数倍レベルで大きく改善し、検知成功率もかなり改善していました。
つまり、より少ない買付保留の数で多くの不正を検知することが、(シミュレーション上ですが)可能になったということになります。
また、モデル推定に既存ルールベースを組み合わせると、買付保留的中率は多少下がりますが検知成功率が大きく改善しました。
上記3つだけのイメージ図を書くと以下のようになります。

この結果からは、機械学習モデルの導入に対する期待値が高まりました。
決定木分析は精度があまり高くないと言われている手法ですので、この後実施するLightGBMならより改善するのでは?とも思えました。
また、指標を事前にすり合わせていたことで、この時点で数字を使った会話ができるようになりました。
数字は仮のものですが、例えば、以下のように整理ができます。
- 既存パターンでは1,000件買付保留を行い100件の不正検知が出来ている。
- モデル推定+既存パターン+新ルール案すべてでは、5,000件買付保留を行い、200件の不正検知が出来る。
- モデル推定+既存パターン+新ルールA案のみでは、2,000件買付保留を行い、195件の不正検知が出来る
数字でイメージがつくので、例えば、買付保留が5倍になっても不正検知を最大化するのか?多少の不正検知数が減っても、買付保留は2倍までに抑えたいか?などの議論を行うことができました。
2.LightGBMを使った機械学習モデルの構築
続いて、LightGBMを使って、機械学習モデルを構築しました。
※LightGBMとはなんぞや?という説明は省略します。非常にメジャーな機械学習モデルですので、興味ある方は調べてみてください。
こちらは、シンプルに(LightGBMによる)モデル推定、既存パターンのみ、モデル推定+既存パターンで精度を比較しました。なお、決定木と比較するとやはりLightGBMのモデル推定の方が精度は高くなっていました。
※予測スコアの閾値の検証なども行っていますが、これも省略しています。
最終的な結果だけ記載しますが、モデル推定+既存パターンでは既存パターンと比較して不正検知率が大幅に改善し、買付保留的中率もそれなりに改善することが確認できました。
買付保留件数も増加していたのですが、ビジネス側で許容範囲と確認いただきました。
コスト面を考えても大きな改善が見込めると検証できたので、機械学習モデルの導入に向けてプロジェクトが動くことになりました。
まとめ
本ケースで行った検証の大まかな流れは以上になります。
機械学習モデルを実際に導入するには時間がかかるため、検証したルールベースの中で精度のよいものをまず導入し、機械学習モデルの導入は順次進めている状況になります。
今回は、明白な結果の差が出たため、導入の判断をすぐに行うことが出来ました。
機械学習の精度がすごいというのはありますが、それとあわせてログとナレッジが大量に溜まっていたことが成功要因でした。
「Garbage in, garbage out」という言葉があります。
精度の高いアルゴリズムでも、ゴミデータを入れればゴミデータしか出てこないという意味ですが、今回は良質なデータのおかげで良質な結果がアウトプットされたと思います。
過去の取り組みまではデータアナリストはなかなか介入できません。
データアナリストとしては、これまでのビジネス側の蓄積された過去のナレッジをうまくヒアリングして、データに変換していくスキルが重要かと思いますが、それらがうまくマッチした事例になれたのではないかと思いました。
本日の記事は以上になります。最後まで読んでいただきありがとうございました。
明日の記事の担当はエンジニアの川本さんです。お楽しみに。
株式会社エニグモ すべての求人一覧