こんにちは。データエンジニアの谷元です。
この記事は Enigmo Advent Calendar 2022 の21日目の記事です。
目次
皆さんどのようにお過ごしでしょうか。 私は昨年に猫ちゃんの可愛さに目覚めてしまい、リモートワーク中も近くで愛猫に見守られる生活を過ごしております。
今年、ねこ検定初級に合格し、愛猫と仲良くなれた気がします🐱 さて、データ基盤の開発運用保守やBI上でのデータ整備などを対応をしてまして、 エニグモは全社的にデータを活用する文化が強く、誰でもデータ活用がしやすいように様々なデータをBigQuery(以下、BQ)に自動集約しております。 規模でいうとデータ基盤上のクエリスキャン量はペタバイト[PB]規模/月であり、 しかし、データ活用が進むにつれて下記の課題を感じていました。 さらに下記の現状もあり、データ基盤の最適化を進めようと思いました。 バッチ処理でBQ連携しており、データ鮮度は原則、最大1時間遅延です。 BQ連携時は差分更新分を連携し、それらのデータから重複や物理削除などを考慮したビュー(以下、最新ビュー)で連携元と同じ最新状態のデータを再現してます。 参考: Apache Airflow で実現するSQL ServerからBigQueryへのデータ同期 汎用的に全ての最新ビューを最適化する方針にしました。理由は下記となります。 最新ビューは差分更新データから再現していたため、不要なスキャンが多すぎる状態でした。 なので、基幹DB全体を定期的にテーブル化し、最新ビューでそのテーブルを利用してスキャン量を改善しようと考えました。 最新ビューの変更方針は以下のとおりです。 図にすると下記のようになります。 尚、BQのマテビューも少し検討したのですが現状では利用制約に引っかかり見送りました。 仕組みからいうと性能は改善するとは思ってましたが、以下の懸念がありました。 あまり時間をかけたくなかったのもあり、下記の確認に留めました。 改善版の最新ビューを用いた効果検証では スキャン量と実行時間共に1/2程度削減 を確認できました。
1/5や1/8程度改善しているケースもあり想定より効果があるのかもと思いました。 尚、定期的なBQ利用状況の効果測定はLooker上のMarketplaceでBQ利用状況が簡単に見れたため、そちらを利用しました。慣れてる方でしたら1日で作成できるかと思います。 実際やってみるとたくさんあった気がするのですが、パッと思い出した話をしてみます。 BQ履歴テーブルを作成開始するにあたり、
その抽出するクエリ内部で参照されているテーブルで必要な情報が揃っている必要があります。 最新ビューは時間軸の異なるデータを複数組み合わせて物理削除も考慮してるため、テーブル毎に依存先DAGや時間軸、依存先のテーブル数も異なります。 図にすると下記となります。 参考: DAG間の依存の話 本番データでの確認期間を少しでも長めに取るため、
本番影響がないよう部分的に先行リリースを繰り返しました。 そうすることで、本番データで確認を進めつつ開発も進められますし、
別件の対応も並行して進めやすくすることも可能でした。 確認期間は2,3週間ほど動かしてエラー検知されなければ大丈夫だろうぐらいで考えてました。 経験上あまり手を抜かない方が良いと考え、バリデーションを入れました。 現状では気になる所だけにしておき、今後必要に応じて増やしていけば良いと考えました。 尚、BigQueryCheckOperatorがシンプルで汎用性が高かったので採用しています。 開発途中でも想定外にエラー検知をしたり、今後の運用でもデータ品質の監視にもなるので、やはり大事だと感じました。 昨今の技術進歩だともっと賢くやる方法があるはずだ!と調べてたら、
Great Expectationsというのがありました。 今回、時間の兼ね合いで検証はできなかったのですが、BQテーブルを自動診断してデータの品質診断結果までファイル出力してくれるようです。 GreatExpectationsOperatorもあるようですし、機会があれば触ってみようかなと思います。 最新ビューには個人情報列あり/なしの2つ存在しており、今までは新規テーブル追加時のオペレーション時はrubyスクリプトを用いてローカルから手動実行して作成してました。 バリデーションで新旧の最新ビューを比較するのに必要でしたし、手動でやるのも手間でしたので、
これを気にAirflow(python)に移植して自動で実行しようと考えました。 対応途中で、よくみると内部でgsutilコマンド使ってることに気づき、 目標リリース期限の2週間前を切っており、効果測定やこのブログを書くタイミングのこともあったので期限をずらしたくなかったのです。 CLI入れるとなると「あれ、間に合うかな。。後回しにしすぎた」となりました(汗 ただ、よく考えると全く同じ方法でやらなくてもいいかと頭を切り替え、 蓋開けたらCLIが移行先で使えなくて、対応期限も近づいてたので慌てたという話ですねw 無事に予定通り、10月末にリリースできまして、その後の話をしたいと思います。 BQクエリコストですが米ドル比較で "前月比 約25%削減" となりました。 桁が大きすぎてよくわからないですね.. BQクエリ平均実行時間ですが、"前月比 約40%削減"されておりました。 最新ビューが絡まないクエリも多数あると思うのですが、
単純な平均でこの数値は思ってた以上に効果があったのかもしれません。 後、10月時点で少し下がってるのはなんでだろう。 LookerではSystem Activity が用意されているので、そちらで確認してみました。 私もダッシュボードをいくつか触ってみましたが、
体感でも「お、ちょっと早くなったな」とわかるぐらいでした。 下記のようにすると、過去のとある時点のデータ参照もできそうでした。 見たい履歴の期間を大きく取りすぎると利用するテーブルによってはデータの参照が遅いですし、やはりスキャン量がやばいことになりそうです。 また、日次のAM0:00時点のみしかBQ履歴テーブルを残してないのもありますので、
傾向を掴むような分析や他に見る参照する方法がない時などの利用用途で向いてそうです。 やはり少し重いですね... 全体を通して概ね計画通りに進められ大きな問題も発生せず、ほっとしました。 スキャン量も右肩上がりだったので、実施タイミングも良かったのかなと思います。 ただ、今回作成したオペレータ数が約数千あって、AirflowのWebUI画面でログ表示しようとしたら少し重くて開きづらくなってました(ぇ) 今後、データ基盤の活用が進むほど、今回対応したコスト削減効果も増えると思います。 データ基盤の開発運用保守に携われている方に少しでも参考になればと思い、このテーマで記事を書いてみました。本記事を通して少しでもイメージを掴めて頂けますと幸いです。 また、お忙しい中、設計の相談やコードレビューをして頂けた上司には感謝しております。 私からは以上となります。最後までお読み頂きありがとうございました。 明日の記事の担当はデータアナリストの井原さんです。お楽しみに。 株式会社エニグモ 正社員の求人一覧はじめに
今回は "データ基盤の処理最適化によるBigQueryコスト削減" の話をさせていただきたいと思います。どうしてデータ基盤を最適化する必要があるの?
前年同月比 約300%での増加傾向にあります。
どうしたら改善できるの?
現状のデータ基盤のおさらい
主要なBUYMA基幹データの最新ビューに着目してみる
最新ビューをどう変更するの?
現状. 月次差分+時間次差分のBQデータを組み合わせる
提案. 日次全件(※)+時間次差分のBQデータを組み合わせる
※ 月次差分+時間次差分でテーブル化、AM0:00固定、以下、BQ履歴テーブルと呼ぶ
システム概要としてはどんな感じ?
尚、白色の箇所は既にあり、今回新規に対応したのは黄色の箇所になります。
この方針で思ったこと
BQ履歴テーブルの作成方針だけど
本当にその方法で改善するの?
運用保守する上で気になっていたこと
見込み効果はどうなの?
実装する上で意識したところ
BQ履歴テーブル作成前提となるDAG依存関係
これらの情報を設定情報として事前に定義した情報から自動で構成しています。
左がExternalTaskSensor、右がBigQueryExecuteQueryOperatorとなり、
右の数だけテーブルがあるようなイメージです。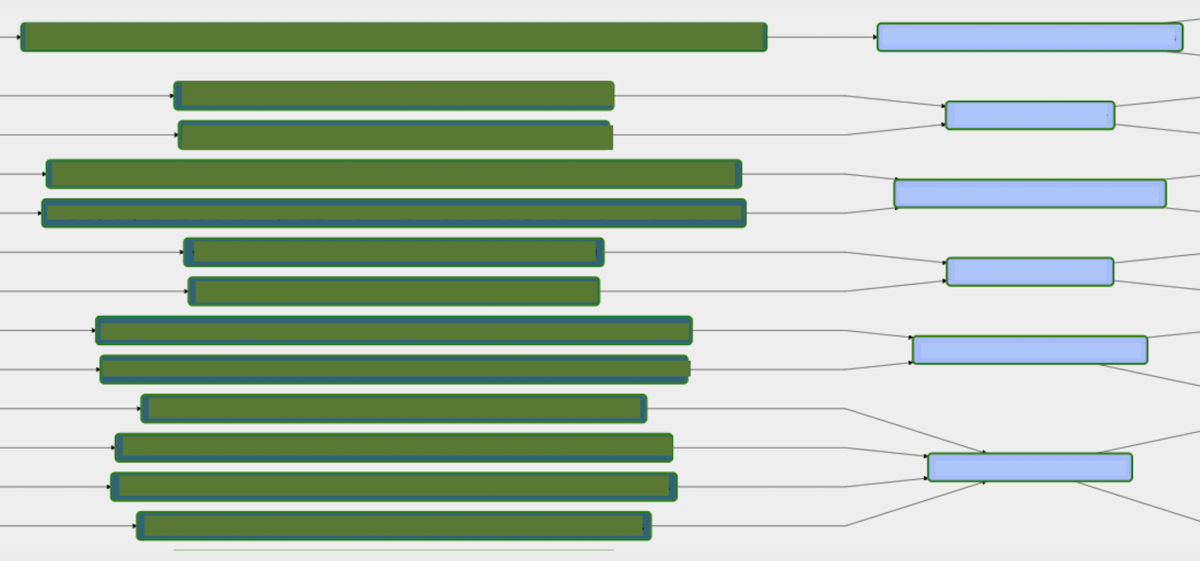
本番データを使った確認期間をできるだけ長めにとろう
データ品質担保はどうしよっかな
今回は見送ったデータ品質対応
既存の手動実行スクリプトをAirflowに移植しようと思ったら
"現行のAirflow環境だとgsutilコマンド(CLI)が入ってなさそうやから使えへんやん!"
となりました。
BQのINFORMATION_SCHEMAやBigQueryHookを使う方法で対応を進めて乗り切りました。そろそろリリース後の話をしよう
効果はどうだったの?
BQクエリコストとそのクエリ数を月次単位で比較してみる(課金対象のみ)
BQクエリスキャン量だとPB(ペタバイト)レベルでの削減です。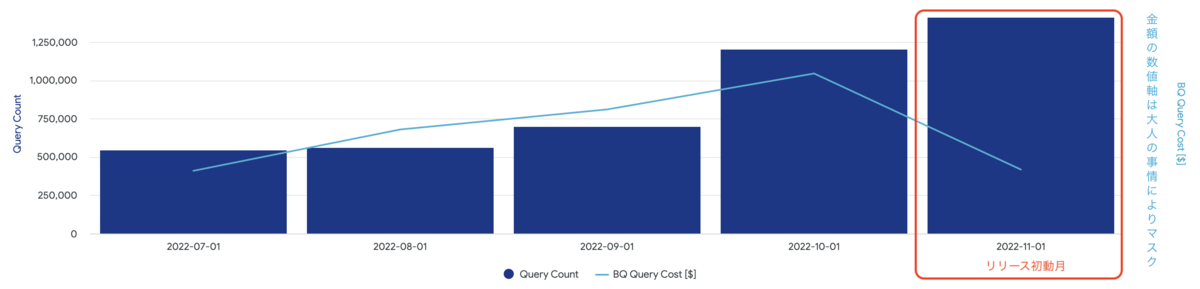
効果測定するにあたって
BQクエリ平均実行時間と処理量を月次単位で比較してみる(課金対象のみ)
先行リリースでバリデーションとかで軽いクエリを流し始めた影響か、
または重たいのが別件で改善されたのですかね。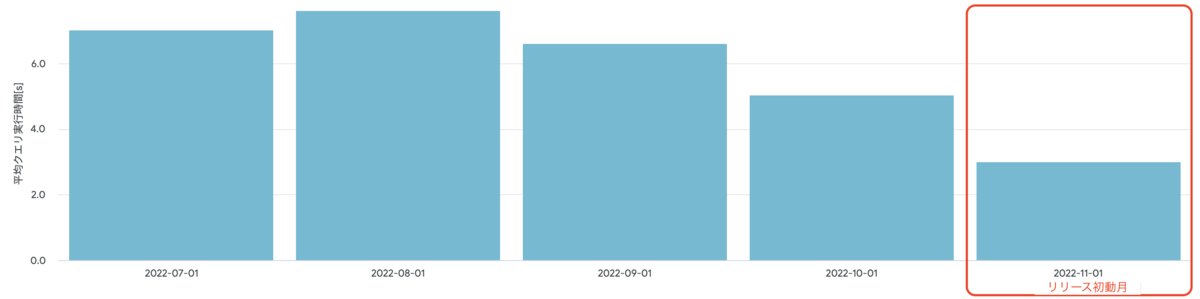
とあるLookerダッシュボード内部のクエリ実行時間を日次で見てみる
やはり半分程度の性能改善がされてそうです。
過去のとある時点のデータを遡ってみる
こんな感じのクエリかな
本来のテーブルリレーションだけ意識すれば良いので楽ですね。DECLARE target_date string;
SET target_date = '20221201';
WITH
_table_a AS (
SELECT _TABLE_SUFFIX AS tabledate, id, value, times
FROM table_a__*
WHERE target_date <= _TABLE_SUFFIX -- 見たい履歴の期間を指定
),
_table_b AS (
SELECT _TABLE_SUFFIX AS tabledate, id, value2
FROM table_b__*
WHERE target_date <= _TABLE_SUFFIX -- 見たい履歴の期間を指定
)
SELECT ta.tabledate, ta.id, ta.value, ta.times, tb.value2
FROM _table_a ta -- BQ履歴テーブル
INNER JOIN _table_b tb -- BQ履歴テーブル
ON ta.id = tb.id -- 本来のテーブル結合条件
AND ta.tabledate = tb.tabledate -- _TABLE_SUFFIX同士で結合する
ORDER BY ta.tabledate, ta.id
タイムリープして思ったこと
Looker上でもexploreを作成してタイムリープしてみた
こんな感じで使うのが良さそうですかね。
所感
懸念してたBQ履歴作成分などで増えるコストもありましたが、それ以上に減少してくれたので良かったです。
また、この機会に手動で実施していた箇所を少し自動化できたのも良かったです。最後に